The National Library of Luxembourg (BnL) has been harvesting the Luxembourg web under the digital legal deposit since 2016. In addition to broad crawls of the entire .lu domain, the Luxembourg Web Archive conducts targeted crawls focusing on specific topics or events. Due to legal restrictions, the web archives of the BnL can only be viewed on the library premises in Luxembourg. BnL joined the IIPC in 2017 and co-organised the 2021 online General Assembly and Web Archiving Conference.
By László Tóth, Web Archiving Software Developer at the National Library of Luxembourg
During the course of 2023, the Bibliothèque Nationale du Luxembourg | National Library of Luxembourg (BnL) undertook the task of migrating its web archive into a new infrastructure. This migration affected all aspects of the archives:
- Hardware: the BnL invested in 4 new high-end servers for hosting the applications related to indexing and playback
- Software: the outdated OpenWayback application was upgraded to a modern pywb/OutbackCDX duo
- Web archive storage: the 339 TB of WARC files were migrated from NetApp NFS to high-performance IBM S3 object storage
In theory, such a migration is not a very complicated task; however, in our case, several additional factors had to be considered:
- pywb has no module for reading WARC data from an IBM-based S3 bucket or communicating with a custom S3 endpoint
- pywb does not know which bucket each resource is stored in
- Our 339 TB of data had to be indexed in a “reasonable” amount of time
In this blog post, we will discuss each of the points mentioned above and provide details on how we overcame these difficulties.
The “before”
Up until December 2023, the BnL offered OpenWayback as a playback engine for users wishing to access the Luxembourg Web Archive. Simple but slow (and somewhat cumbersome to use), OpenWayback lacks a number of features required for an ergonomic user experience and efficient browsing of the archive.
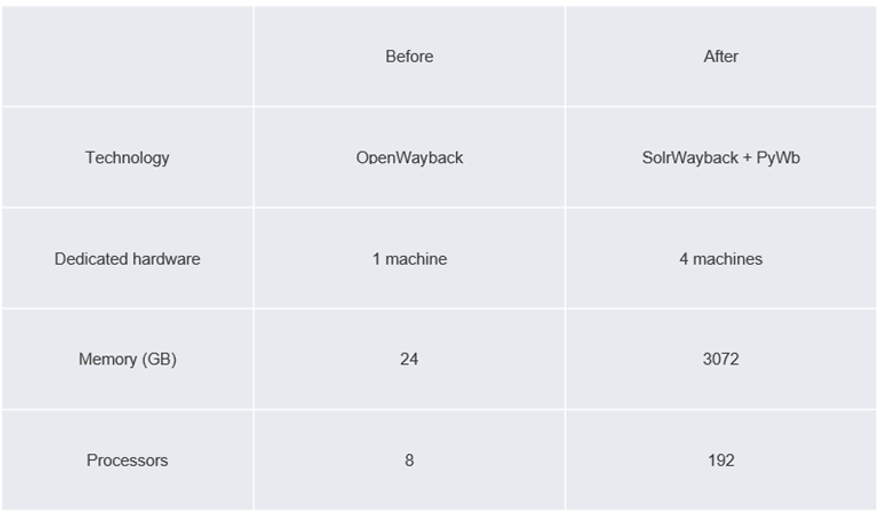
The WARC files were stored on locally mounted NFS shares, and the server handling the archive and serving OpenWayback to clients was a virtual machine with 8 cores and 24 GB of RAM.
One of the big drawbacks of this setup was the way indexes were handled. These were stored in CDX files at the rate of one file per collection, resulting in a loaded OpenWayback configuration file:
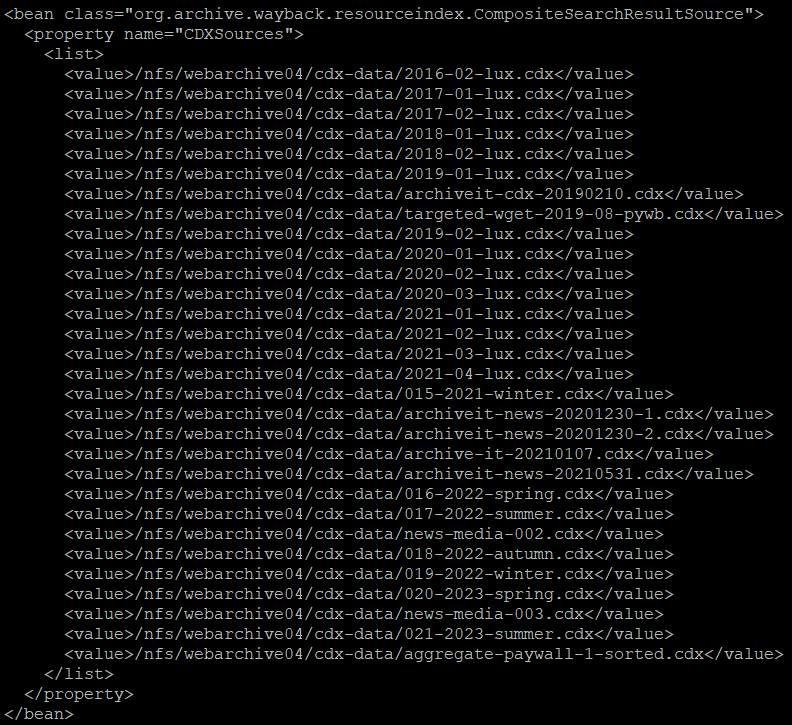
In order for OpenWayback to access a given resource, it first had to find it; thus, the main source of loading times came from the size of the CDX files (3.1 TB in total) and the slowness of the NFS drive they were stored on. Furthermore, every time a new collection was added or a new WARC file indexed into the archive, the Tomcat web server had to be restarted, resulting in a few minutes of downtime.
The slow loading of the pages meant that users were not encouraged to visit our web archive.
Planning the update
In order to improve the BnL’s offerings to users, we decided to address these problems by switching to pywb, the popular playback engine developed by Webrecorder, and OutbackCDX, a high-performance CDX index server developed by the National Library of Australia.
For hosting these applications, and with a future SolrWayback setup in mind, the BnL purchased 4 high-end servers, boasting 96 CPUs and 768 GB RAM each.
The migration to S3 storage
Although not necessary for installing those new applications, we decided to migrate to S3 before installing pywb and Solrwayback. This is because our state IT service provider had successfully implemented a storage system based on S3 and had a positive experience with it performance-wise compared to using NFS. Since the web archive consumes a sizable chunk of their storage infrastructure, we made a joint strategic decision to move to S3. Migrating the storage layer at the point while we were migrating the access systems made sense, so this was done first.
This entailed several additional tasks:
- Setting up a database to store the S3 location of each WARC file together with various metadata, such as integrity hashes and harvest details for each file
- Physically copying 339 TB WARC files to S3 buckets
- Developing a pywb module to read WARC data directly from IBM S3 buckets and another module to get the S3 bucket characteristics from the database
We began by setting up a MariaDB database with a few tables for storing file and collection metadata. Here is an example entry in the table “file”:

We then copied the files to S3 storage using a simple multithreaded Python script that used the ibm_boto31 module to upload files to S3 buckets and compute various pieces of metadata. We divided our web archive into separate collections, each stored in a single bucket and corresponding to a specific harvest made within a specific time period by a specific organization. Our naming scheme also includes internal or external identifiers if there are any. For instance, files that were harvested by the Internet Archive during the 2023 autumn broad crawl, having the ID #22, are stored in a bucket named “bnl-broad-022-2023-autumn”, while those collected during the second behind-the-paywall campaign of 2023 are stored in “bnl-internal-paywall-2023-2”. In total, we have 32 such buckets.
Finally, we developed pywb modules to ensure that every time the application requests WARC data, it first queries the aforementioned database to find out which bucket the resource is in, and then loads the data from the requested offset up to the requested length. Of course, we didn’t allow direct communication between pywb and our database, so we developed a small Java application with a REST API whose sole purpose is to facilitate and moderate such a communication.
At this point, we’d like to note that pywb already has an S3Loader class; however, this is based on Amazon S3 technology and does not allow defining a custom endpoint for communicating with the S3 service itself. In order to adapt this to our needs, we modified pywb by implementing a BnlLoader class that extends BaseLoader, which does all the above and uses ibm_boto3 to get the WARC data. We then mapped it to a custom loader prefix in the loaders.py file:
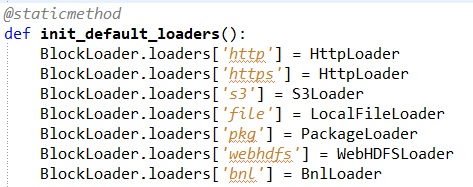
Notice our special class on the last line in the figure above. Now in order for pywb to use this class, it has to be referenced in the config file. Here is what the relevant part of our config file looks like:
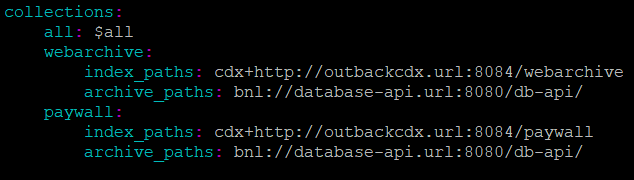
Note the “bnl://” prefix in “archive_paths”: this tells pywb to load the BnlLoader class as the WARC data handler for the corresponding collection. The value of this key is simply the URL linking to our database API server that we mentioned above, which allows controlled communication with the underlying MariaDB database.
So, in summary:
- pywb needs to load a resource from a WARC file
- The BnlLoader class’ overridden load() method is called
- In this method, pywb makes an API call to our REST API service in order to get the S3 bucket where the WARC is stored via the database
- The S3 path that is returned is then used together with the requested offset and length (provided by OutbackCDX) to make a call to the IBM S3 cluster using ibm_boto3
- pywb now has all the data it needs to display the page
The result can be summarized in the following workflow diagram:
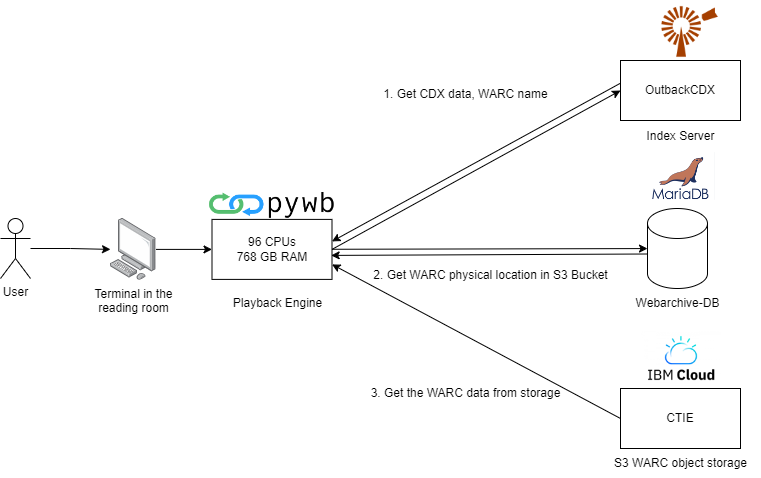
Note that OutbackCDX and pywb are set up on the same physical server, having 96 CPUs and 768 GM RAM; however, on the diagram above, we have shown them separately for the purpose of clarity.
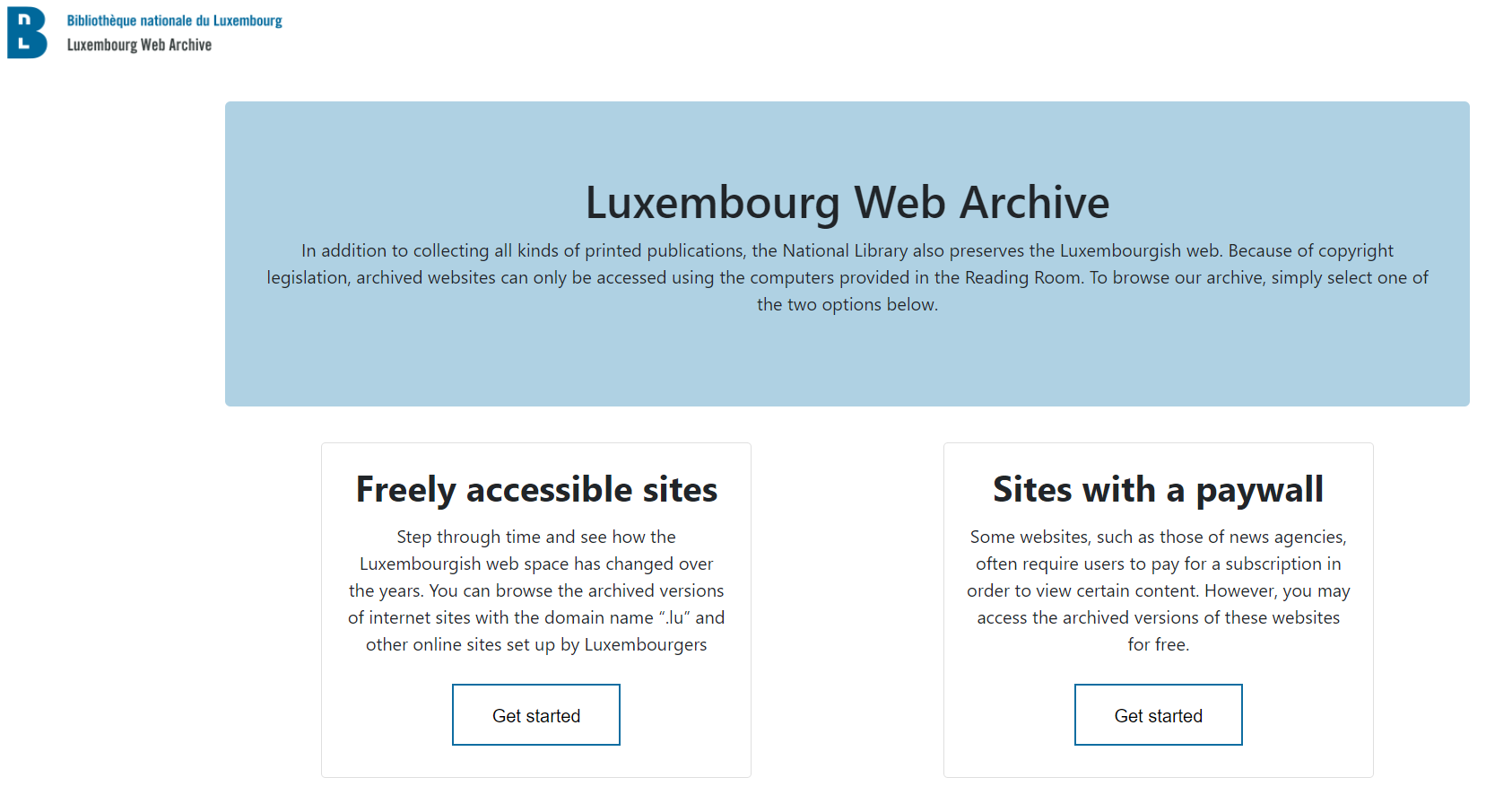
Our new access portal
Our access portal to the web archives was also completely redesigned using pywb’s templating engine, which allows us to fully customize the appearance of almost all elements in the interface. We decided to provide our users with two main sub-portals: one for accessing websites harvested behind paywalls, and another one for everything else. We had two main reasons for this:
- Several of our collections contained harvests of paywalled versions of websites. We did not want to mix these together with the un-paywalled versions,
- We wanted to offer our users a clear distinction between open (“freely accessible”) content and un-paywalled content.
The screenshot below shows our main access portal:
Next steps
2024 will see the installation of Netarkivet’s SolrWayback at the BnL, providing advanced search features such as full-text search, faceted search, file type search, and many more. Our hybrid solution will use pywb as the playback engine while SolrWayback will be responsible for the search aspects of our archive.
The BnL will also provide an additional NSFW-filter and virus scan in SolrWayback. During indexing, the content inside the WARC files will be scanned using artificial intelligence techniques in order to label each one as “safe” or “not safe for work” material. This way, we will be able to restrict certain content, such as pornography, in our reading rooms and block other harmful elements, such as viruses.
Finally, the BnL will develop an automated QA workflow, aiming at detecting and patching missing elements after harvests. Since this work is currently being done manually by a student helper, this workflow will likely greatly increase the quality and efficiency of our in-house harvests.
Resources
- From the IIPC blog
- From GitHub
Footnotes
- Link to Python module and documentation ↩︎
 In line with the broader content development policy, CDG collections focus on topics that are transnational in scope and are considered of high interest to IIPC members. Each collection represents more perspectives than similar collections by a single member archive may include. Nominations are submitted by IIPC members, who have been archiving the conflict as early as January 2022 (see below) as well as the general public.
In line with the broader content development policy, CDG collections focus on topics that are transnational in scope and are considered of high interest to IIPC members. Each collection represents more perspectives than similar collections by a single member archive may include. Nominations are submitted by IIPC members, who have been archiving the conflict as early as January 2022 (see below) as well as the general public.
 One of the largest volunteer initiatives focusing on preserving Ukrainian web content has been
One of the largest volunteer initiatives focusing on preserving Ukrainian web content has been 




















