
By Kristinn Sigurðsson, Head of Digital Projects and Development
at the National and University Library of Iceland
and the IIPC Chair 2022-2023
Hi all,
It is my pleasure to serve as Chair of the IIPC Steering Committee and the Executive Board for 2022. I’ve been a part of this community in one way or another since the start. I’ve often stated that without our involvement in the IIPC, the Icelandic web archive here at the National and University Library of Iceland would be a shadow of its current self.
An Organization for All Seasons
Despite the challenges of the pandemic, I’m very happy that the IIPC has been able to maintain an extensive and ambitious program over the last couple of years. This was very important as, in the past, the IIPC’s in-person events – notably our General Assembly (GA) and Web Archiving Conference (WAC) – have been at the core of IIPC activity.
The IIPC community is incredibly positive, energetic and creative, and this is always on full display when we meet in person. Over the years we’ve tried very hard to sustain the energy and shared feeling of purpose throughout the year. Even before the pandemic, we made sure the community could meet online during our regular technical calls, webinars and workshops.
These earlier efforts left us with a foundation to build upon, and I’m very happy with what we have been able to deliver. We have had even more events these past two years, including our first online conference co-hosted by the National Library of Luxembourg. My deepest thanks to Olga and everyone who helped make that possible.
Unfortunately, it seems we face another year without any significant in-person events. Rest assured, however, that we will continue with our program of meetings, workshops, members updates, webinars featuring web archiving initiatives (including the IIPC funded projects) and, of course, a virtual GA and conference in late May.
This transformation from an organization that sometimes seemed to disappear in the off season to one that is active year round has been very satisfying from my perspective. This “disappearance” was always a bit of an illusion, as there was always some work and collaboration going on, but the added visibility and opportunities for engagement have been crucial.
As we look forward to resuming in-person events next year (fingers crossed), it is important that we do not forget any of the lessons we have learned from this. It is important that we do not simply go back to things as they were, but that we retain this online aspect of the organization all year round. With that in mind, much of this year we will be looking to establish a more predictable and consistent schedule of events, allowing our progress to carry on into future years.
Of course, all of this has required a fair amount of work and will continue to do so, bringing me to our next topic.
Reinforcement
As the IIPC has expanded and matured, the duties and responsibilities of our sole employee have grown considerably. Recognizing that this had reached an unsustainable point, last year the Steering Committee authorized the hiring of one additional full-time staff member for the new role of Administrative Officer. The Administrative Officer will take some of the more routine, administrative, duties off of our Senior Program Officer’s plate and support her as needed.
The position was advertised in November and prospective candidates were interviewed in late December and early January. After concluding our search, we hired Kelsey Socha as the new Administrative Officer for the IIPC. Kelsey Socha holds a BFA in Theatrical Design and Production from the University of Michigan, and an MS in Library and Information Science from Simmons University. She has served in a variety of library roles, most recently as Head of Adult Services for the Westfield Athenaeum in Westfield, Massachusetts. She began work for the IIPC on February 9th. Both the Administrative Officer and the Senior Program Officer roles are hosted by Council of Library and Information Resources (CLIR).
With this reinforcement, I feel confident that we will be able to rise to the ambitious schedule I discussed earlier.
Executive Board
Two years ago, we revised and renewed our Consortium Agreement, which among other changes introduced an Executive Board (EB), composed of the Chair, Vice-Chair, Treasurer, Senior Program Officer and, optionally, up to two other Steering Committee members. Aside from the Senior Program Officer, appointments are for 1 year. The EB was set up to create a smaller and more responsive body to manage the practical aspects of running the IIPC and to liaise with CLIR, our financial and administrative host. The first Board started work in January 2021 and this new setup has made our governance more agile. I would like to take this opportunity to thank Sylvain Bélanger of Library and Archives Canada, who served as IIPC Treasurer, and to welcome Ian Cooke of the British Library who has taken on this role. My long-term IIPC colleague Abbie Grotke has volunteered to serve as the Vice-Chair. My thanks also go to Hansueli Locher of Swiss National Library, who served on the EB last year.
The Steering Committee will continue to focus on our longer-term policy as well as oversight, with members of our three Portfolios and being actively involved the areas outlined in our Strategic Plan.
New Steering Committee Members
I would also like to take this opportunity to welcome the two newly elected SC members, Bjarne Andersen on behalf of the Royal Danish Library and Tobias Steinke on behalf of the German National Library.
Each year, about one-third of the fifteen SC seats are up for reelection. I’ve been pleased to observe over the last few years that these elections have gotten more competitive with more members seeking to serve. As the active involvement of our members is vital to the IIPC long term success, I’m confident that this is a positive sign.
Tools
Just recently, a project commissioned by our Tools Development Portfolio (TDP) to improve the open source web archive replay tool PyWb was completed. I wrote about this project back when it was just starting (read post). Now, Ilya Kreymer, PyWb’s developer, has delivered the last of the work agreed upon. There will be more in-depth posts about this soon, and you can also find all the blog posts on interim work here.
This PyWb project is the first funded development project to be managed by the TDP and overall, I’m very pleased with the outcome. I would like to take this opportunity to thank the other members of the TDP, Lauren Ko, Alex Osborne and Youssef Eldakar, for all their hard work. Even our funded projects still depend on a fair amount of volunteer effort. Partly based on the experience from this project, the TDP is currently working on another project with Ilya Kreymer, this time focused on browser-based crawling.
Browser-based crawling was identified as a key capability that is largely lacking in our tool suite at an online Tools Workshop with IIPC members held in June 2021. Based on discussions there, several of our member organizations put together a project plan to address this. The project will involve notable extensions to the Webrecorder software to facilitate better browser-based crawling. Unlike the PyWb project, however, this project also includes considerable commitments on behalf of 4 member organizations (British Library, National Library of New Zealand, Royal Danish Library and University of North Texas) that are not funded by the IIPC.
This project is expected to last two years, and we plan to keep you informed throughout. Members interested in participating should keep an eye out for upcoming announcements and posts here.
20th Anniversary
Next year will be the IIPC’s 20th anniversary. A lot has changed since the original 12 members signed the first Consortium Agreement back in 2003. The fact that such a milestone looks to also align with a return to in-person events after three years without them gives us even more cause to strive for the best General Assembly and Web Archiving Conference ever (as if we ever aimed lower).
Even as we work on the substantial online slate of events for 2022 that I mentioned above, work has already begun on this return to normalcy. You can be part of this too. Keep an eye out for the call for a hosting institution, participation in our program committee, and the call for papers.
Lastly, please feel free to reach out to me if you have any questions or concerns during my time as Chair.
Kristinn Sigurðsson,
Head of Digital Projects and Development at the National and University Library of Iceland
IIPC Chair 2022-2023
This slideshow requires JavaScript.

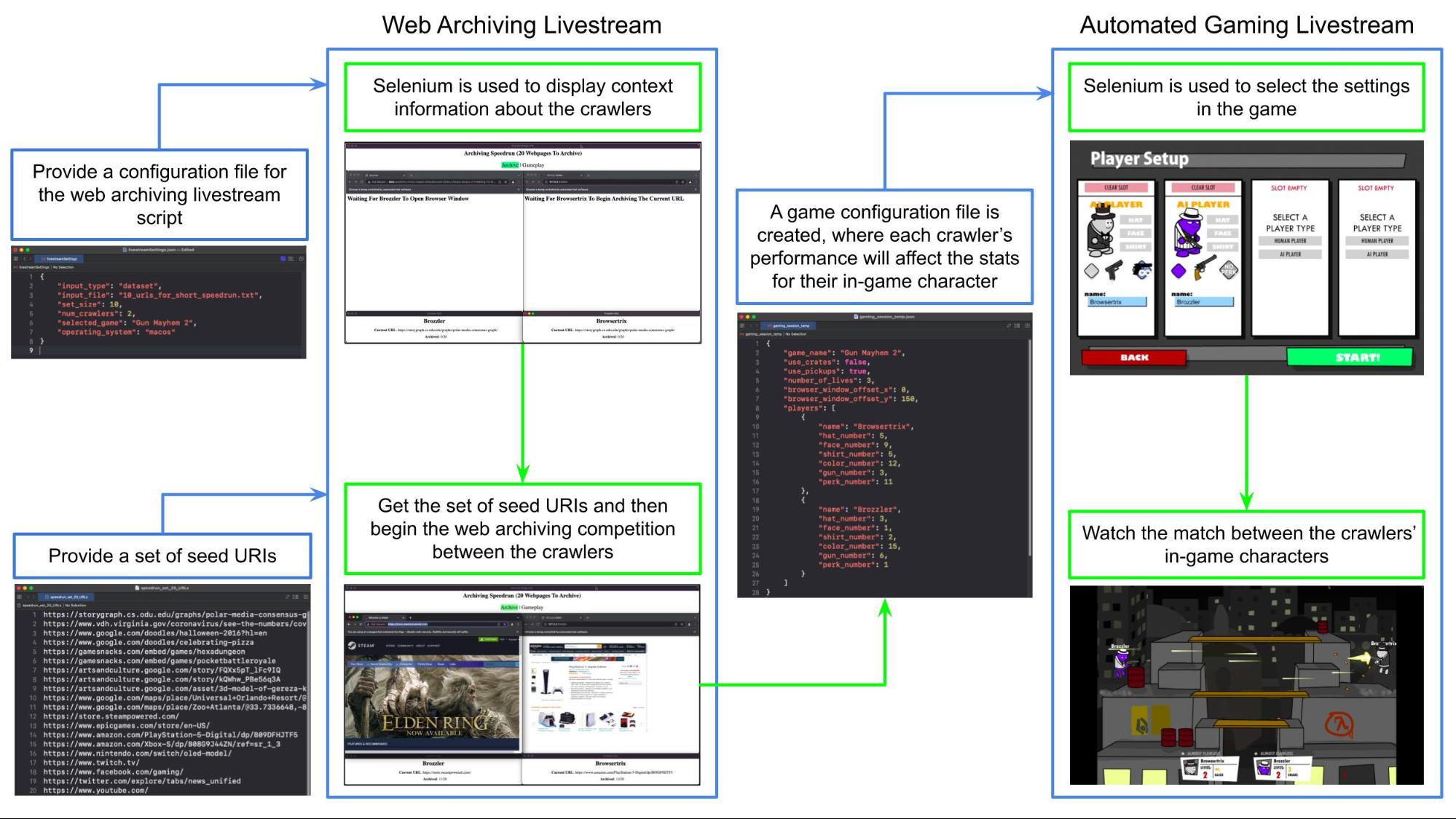









 By Kristinn Sigurðsson, Head of Digital Projects and Development at the National and University Library of Iceland, and Georg Perreiter, Software Developer at the National and University Library of Iceland.
By Kristinn Sigurðsson, Head of Digital Projects and Development at the National and University Library of Iceland, and Georg Perreiter, Software Developer at the National and University Library of Iceland.


 The IIPC is governed by
The IIPC is governed by



