By Friedel Geeraert, Expert in web archiving at KBR | Royal Library of Belgium
This year’s IIPC General Assembly and Web Archiving Conference took place at the Bibliothèque nationale de France (BnF) in Paris. It was wonderful to be welcomed once again into the warm web archiving community, especially in the superb surroundings the BnF had to offer. The welcome reception in the oval reading room at the BnF Richelieu site was especially memorable in that respect. Other than the lovely encounters with web archiving colleagues from around the world, the General Assembly and the Web Archiving Conference program had a lot to offer.
Opening remarks by the President of the BnF, Gilles Pécout, in Salle Ovale. Photo credit: Guillaume Murat, BnF
The General Assembly gave insight into the strategic plan for 2026-2031 and the reflections of the Steering Committee during their meeting that took place the day before. The transparency about their discussions and the active call for participation of members in determining the strategic priorities of the IIPC was greatly appreciated. The historical overview of the changes that have taken place in the Consortium Agreement was also fun to see, as it showed how the IIPC has grown as an organization over the decades.
Workshops offered participants opportunities to gain hands-on experience in becoming confident trainers in the domain of web archiving, running your own full stack SolrWayback, and crawling using the Browsertrix Cloud, among others. Panel discussions and keynotes allowed for deepening one’s knowledge about Skyblog (a French pioneer in social networks), the archivability of websites, archiving social media, and training Large Language Models. Sessions focused on a myriad of subjects such as capturing unique content (ads, digital artworks, memes, etc.), digital preservation, and planning (tenders, sustainability of web archiving programs, training, etc.). The poster sessions and the drop-in and lightning talks allowed participants to gather information on a whole range of concepts very efficiently.
This is only a selection of themes that were covered during the conference. The program comprised three parallel sessions, all covering interesting topics, thereby inspiring a significant level of FOMO in participants.
Friedel Geeraert presenting a KBR drop-in talk. Photo credit: Olga Holownia.
At KBR, there are currently three projects in the pipeline:
Setting up a web archive on a voluntary basis (via a public tender)
Extending the legal deposit legislation to online content
TheBelgicaWeb research project. The project is funded by BELSPO, the Belgian Science Policy Office, through the BRAIN 2.0 program and aims to make the born-digital heritage of Belgium accessible and FAIR.
Bearing in mind this institutional context, a number of elements evoked during the General Assembly and Web Archiving Conference are particularly useful. Within the BelgicaWeb project, we will further look into SolrWayback and Browsertrix Cloud. APIs offered by organizations such as Arquivo.pt are also sources of inspiration. Initiatives such as Datasheets for Web Archives by Emily Maemura and Helena Byrne can also prove useful in describing the provenance of collections of archived web content. Using PWIDs to reference web sources archived in certain web archive collections has also been adopted as best practice within the BelgicaWeb project.
As a member of the Preservation Working Group at KBR, I found the session on Digital Preservation especially useful. The Danish Royal Library proved itself once again as one of the leading examples in Europe where digital preservation of born-digital content is concerned. Thanks to their presentations, we will be looking further into Bitrepository.org.
All in all, this was another great edition of the IIPC GA & WAC. I can’t wait for the next conference in Oslo!
The IIPC is governed by the Steering Committee, formed of representatives from fifteen Member Institutions who are each elected for three-year terms. The Steering Committee designates the Chair, Vice-Chair and Treasurer of the Consortium. Together with the Senior Program Officer, based at the Council on Library and Information Resources (CLIR), the Officers make up the Executive Board and are responsible for dealing with the day-to-day business of running the IIPC.
The Steering Committee has designated Jeffrey van der Hoeven of KB, the National Library of the Netherlands to serve as Chair and Andrea Goethals of the National Library of New Zealand to serve as Vice-Chair in 2024. Bjarne Andersen of the Royal Danish Library will serve as the IIPC Treasurer. Olga Holownia continues as Senior Program Officer, Kayla Martin-Gant is now Administrative Officer, and CLIR remains the Consortium’s financial and administrative host.
The Members and the Steering Committee would like to thank Youssef Eldakar of Bibliotheca Alexandrina for leading the IIPC in 2023 and Ian Cooke of the British Library for his two-year term as the IIPC Treasurer.
IIPC CHAIR
Jeffrey van der Hoeven, IIPC Chair
Jeffrey van der Hoeven is head of the Digital Preservation department at the National Library of the Netherlands (KB). In this role, he is responsible for defining the policies, strategies, and organizational implementation of digital preservation at the library, with the goal to keep the digital collections accessible to current users and generations to come. Jeffrey is also director at the Open Preservation Foundation (OPF) and has been a member of the IIPC Steering Committee since 2020. In previous roles, he was involved in various national and international preservation projects such as the European projects PLANETS, KEEP, PARSE.insight, and APARSEN.
IIPC VICE-CHAIR
Andrea Goethals, IIPC Vice-Chair
Andrea Goethals started her digital preservation career in 2003 as a computer scientist working on technical strategies for handling format obsolescence. Since then, she has worked in roles focusing on the policies, strategies, and people that make digital preservation programs possible. She is now Manager of Digital Preservation and Data Capability (Kaiwhakahaere Rokiroki ā-Matihiko me te Āheinga Raraunga) at the National Library of New Zealand, where she leads a team of specialists with expertise in digital preservation, web archiving, software development, and data analysis. She runs the NZ DOI Consortium and participates in many regional and international groups, including iPRES Steering Group, Australasia Preserves, Digital Preservation Storage Criteria WG, DataCite CESG, and NSLA Digital Preservation Network.
IIPC TREASURER
Bjarne Andersen, IIPC Treasurer
Bjarne Andersen is Head of the Data Department at the Royal Danish Library (KB). In this role, he is responsible for IT-development of systems handling ingest and digital preservation of digital cultural heritage. Apart from managing IT-developers, Bjarne is also in charge of enterprise IT-architecture at KB and involved in setting up a new AI and Data initiative at the library. Bjarne started more than 20 years ago building the national web archive Netarkivet and has held many different roles since. Bjarne was on the founding board of directors of OPF following the involvement in European Projects DPE, PLANETS and SCAPE – all around Digital Preservation.
By Andy Jackson, Web Archiving Technical Lead at the British Library (until January 2024)
I joined the UK Web Archive early in 2012, during the build-up to our very first UK domain crawl. As I started to understand what the team did, it became very clear that the collaboration with the wider IIPC web archiving community had been crucial to the team’s success, and would be a vital part of our future work.
The knowledge sharing and socialising at the IIPC conferences provide the fundamental rhythm, but the web archiving community has arranged all sorts of beats over that bass drum. Not just special events, both online and in person (e.g. technical training and a hackathon held at the British Library), but also through the way we build our shared tools. My research career had often involved using open source software, but in web archiving I began to understand how those same approaches had been used to share the load of developing standard practices, embodied by specialist tools. I also began to see how this could empower people and organisations to run their own web archiving operations.
Buy or Build?
While the public awareness of web archiving has certainly risen over the years, it remains something of a niche concern. It has been over twenty years since a small group of cultural heritage organisations kicked things off, writing and sharing their own tools to archive the web. In the intervening years the heritage community has grown a great deal, but most of today’s archival web crawlers are still built on those first foundations. There seems to be a reasonable market for ‘medium-scale’ web archiving, with a few different vendors offering various services at that scale. But at the extremes, with personal web archiving at one end and Legal Deposit domain crawls at the other, there are all sorts of constraints that make it difficult to take advantage of those commercial offerings.
Sometimes, you have to build your own tools. But, if you must build your own, you can try to find others with similar needs and look for common ground to share. Open source licences and development practices have clearly been pivotal to helping this happen in web archiving, leading to the widespread use of Heritrix for web crawling and of the original Java Wayback playback engine. This was a success story I wanted to join in with, and a community I wanted to help grow.
Barriers to Collaboration
Seeing this historical success, I took it for granted that of course our institutions would understand and support this. That anyone using these tools would be able and keen to collaborate. Why keep fixing the same bugs alone when we could fix each one once by working together?
That was very naive of me. There are lots of reasons why the open source model of collaboration can be difficult to adopt. The relationships between organisational needs and Information Technology service delivery are incredibly varied and complex. It can be very difficult to get the space and permission to experiment. It can be extremely difficult to build up or pull in the skills we need.
Even where people would like to collaborate more, there are often perfectly understandable personal or professional constraints that mean they can’t just pitch in. I am very fortunate that my direct managers and colleagues at the British Library supported my strategy of working in the open. I am also fortunate that I risk very little by doing so. It took me a while to realise what a privilege that is.
The desire to overcome these barriers was part of the reason why I helped start up the regular Online Hours calls to support the teams and individuals who rely on our shared tools, and provide a safe and friendly forum for anyone who is interested in talking about them.
In January, I left the British Library to work at the Digital Preservation Coalition. I suspect I’ll reconnect with web archiving at some point in the future, in one form or another, but for now, I’m looking forward to taking what I’ve learned and applying it anew. Because at some point I realised that open source isn’t just about making do with not-much money. It’s about digital preservation too.
Critical Dependencies
One of the core concepts in digital preservation is the idea of Representation Information, which provides a way to formally recognise the additional information we need to make our collections accessible. Crucially, this includes software. After all, the thing that makes digital objects digital is the fact that we need software to use them.
This is where proprietary systems can become a significant risk to digital preservation. Perhaps the most important part of digital preservation is identifying single points of failure within the chain of dependencies that access requires. If playback depends on a single service provider, it’s at risk. Long-term preservation demands interoperability, which is why the WARC standard exists in the first place.
The WARC standard is our foundation stone, but that alone is not enough to make those frozen fragments sing. We can’t grasp what landed in our ‘response’ records without being able to understand the mechanisms that put them there. And we can’t analyse and explore our petrified webs without the software tools that bring them to life. There is no ‘ISO standard for playback’ (and I doubt such a thing is even possible), so we must instead preserve the software that makes playback work. This is why having at least one open source playback system is a crucial concern for the members of the IIPC.
But this is not just true for web archiving. This same story plays out across the whole of digital preservation. The wider shift to open source, and the work that the global community has put into open source implementations of widespread formats, has become the backbone of every digital preservation programme. We’re not out here re-implementing libtiff, or writing PDF readers based on the ISO spec. We’re all re-using open source implementations that are being maintained by the wider community. We’re all in the business of preserving software, at least to some degree.
Communities of Practice
The success of the community-maintained Web Archiving Awesome List, the way organisations have transitioned to pywb (like this) and the growing support for Browsertrix Cloud show that the web archiving community understands this. That one way to sustainable, shared practices is through shared tools as well as common purpose. These tactics don’t only help established archives do their work, but also make it easier for ‘younger’ archives to join in and so grow the community around those tools.
My new role is all about helping digital preservation practitioners discover and build on the good practice of others. I will take what I’ve learned from web archiving with me, and come back to this community as an exemplar of what we can achieve when we work together.
The National Library of Luxembourg (BnL) has been harvesting the Luxembourg web under the digital legal deposit since 2016. In addition to broad crawls of the entire .lu domain, the Luxembourg Web Archive conducts targeted crawls focusing on specific topics or events. Due to legal restrictions, the web archives of the BnL can only be viewed on the library premises in Luxembourg. BnL joined the IIPC in 2017 and co-organised the 2021 online General Assembly and Web Archiving Conference.
By László Tóth, Web Archiving Software Developer at the National Library of Luxembourg
During the course of 2023, the Bibliothèque Nationale du Luxembourg | National Library of Luxembourg (BnL) undertook the task of migrating its web archive into a new infrastructure. This migration affected all aspects of the archives:
Hardware: the BnL invested in 4 new high-end servers for hosting the applications related to indexing and playback
Software: the outdated OpenWayback application was upgraded to a modern pywb/OutbackCDX duo
Web archive storage: the 339 TB of WARC files were migrated from NetApp NFS to high-performance IBM S3 object storage
In theory, such a migration is not a very complicated task; however, in our case, several additional factors had to be considered:
pywb has no module for reading WARC data from an IBM-based S3 bucket or communicating with a custom S3 endpoint
pywb does not know which bucket each resource is stored in
Our 339 TB of data had to be indexed in a “reasonable” amount of time
In this blog post, we will discuss each of the points mentioned above and provide details on how we overcame these difficulties.
The “before”
Up until December 2023, the BnL offered OpenWayback as a playback engine for users wishing to access the Luxembourg Web Archive. Simple but slow (and somewhat cumbersome to use), OpenWayback lacks a number of features required for an ergonomic user experience and efficient browsing of the archive.
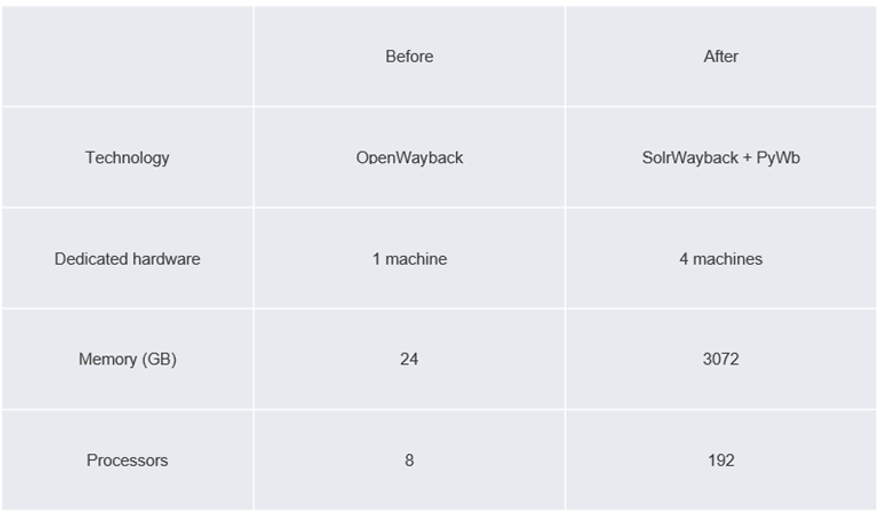
The WARC files were stored on locally mounted NFS shares, and the server handling the archive and serving OpenWayback to clients was a virtual machine with 8 cores and 24 GB of RAM.
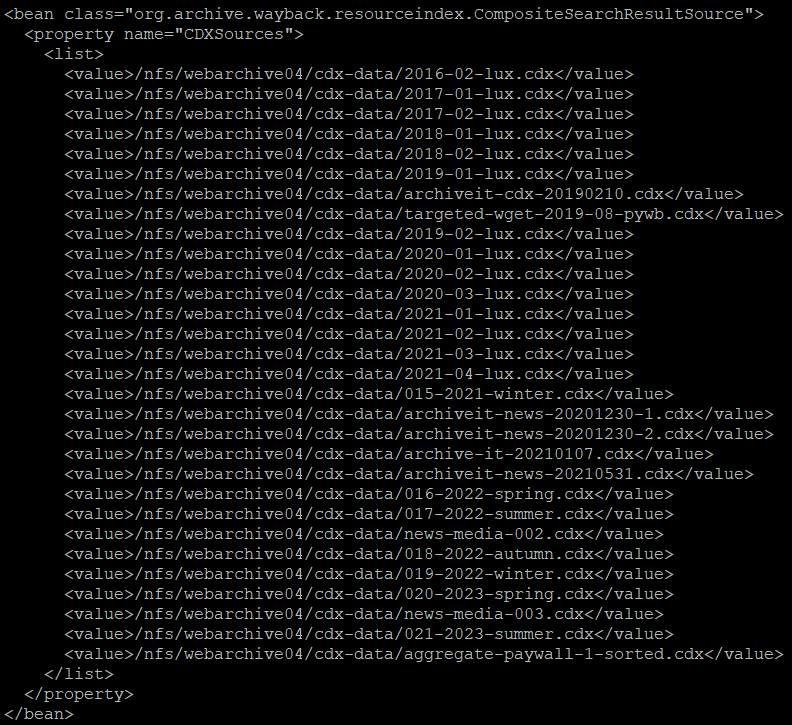
One of the big drawbacks of this setup was the way indexes were handled. These were stored in CDX files at the rate of one file per collection, resulting in a loaded OpenWayback configuration file:
Figure 1: There has to be a better way of doing this…
In order for OpenWayback to access a given resource, it first had to find it; thus, the main source of loading times came from the size of the CDX files (3.1 TB in total) and the slowness of the NFS drive they were stored on. Furthermore, every time a new collection was added or a new WARC file indexed into the archive, the Tomcat web server had to be restarted, resulting in a few minutes of downtime.
The slow loading of the pages meant that users were not encouraged to visit our web archive.
Planning the update
In order to improve the BnL’s offerings to users, we decided to address these problems by switching to pywb, the popular playback engine developed by Webrecorder, and OutbackCDX, a high-performance CDX index server developed by the National Library of Australia.
For hosting these applications, and with a future SolrWayback setup in mind, the BnL purchased 4 high-end servers, boasting 96 CPUs and 768 GB RAM each.
Figure 2: Hardware comparison – before and after
The migration to S3 storage
Although not necessary for installing those new applications, we decided to migrate to S3 before installing pywb and Solrwayback. This is because our state IT service provider had successfully implemented a storage system based on S3 and had a positive experience with it performance-wise compared to using NFS. Since the web archive consumes a sizable chunk of their storage infrastructure, we made a joint strategic decision to move to S3. Migrating the storage layer at the point while we were migrating the access systems made sense, so this was done first.
This entailed several additional tasks:
Setting up a database to store the S3 location of each WARC file together with various metadata, such as integrity hashes and harvest details for each file
Physically copying 339 TB WARC files to S3 buckets
Developing a pywb module to read WARC data directly from IBM S3 buckets and another module to get the S3 bucket characteristics from the database
We began by setting up a MariaDB database with a few tables for storing file and collection metadata. Here is an example entry in the table “file”:
Figure 3: Some WARC file metadata in our DB
We then copied the files to S3 storage using a simple multithreaded Python script that used the ibm_boto31 module to upload files to S3 buckets and compute various pieces of metadata. We divided our web archive into separate collections, each stored in a single bucket and corresponding to a specific harvest made within a specific time period by a specific organization. Our naming scheme also includes internal or external identifiers if there are any. For instance, files that were harvested by the Internet Archive during the 2023 autumn broad crawl, having the ID #22, are stored in a bucket named “bnl-broad-022-2023-autumn”, while those collected during the second behind-the-paywall campaign of 2023 are stored in “bnl-internal-paywall-2023-2”. In total, we have 32 such buckets.
Finally, we developed pywb modules to ensure that every time the application requests WARC data, it first queries the aforementioned database to find out which bucket the resource is in, and then loads the data from the requested offset up to the requested length. Of course, we didn’t allow direct communication between pywb and our database, so we developed a small Java application with a REST API whose sole purpose is to facilitate and moderate such a communication.
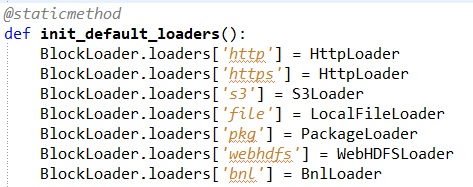
At this point, we’d like to note that pywb already has an S3Loader class; however, this is based on Amazon S3 technology and does not allow defining a custom endpoint for communicating with the S3 service itself. In order to adapt this to our needs, we modified pywb by implementing a BnlLoader class that extends BaseLoader, which does all the above and uses ibm_boto3 to get the WARC data. We then mapped it to a custom loader prefix in the loaders.py file:
Notice our special class on the last line in the figure above. Now in order for pywb to use this class, it has to be referenced in the config file. Here is what the relevant part of our config file looks like:
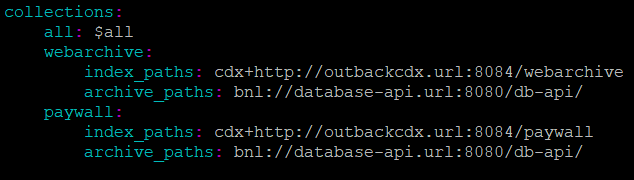
Figure 5: Our configuration file (config.yaml)
Note the “bnl://” prefix in “archive_paths”: this tells pywb to load the BnlLoader class as the WARC data handler for the corresponding collection. The value of this key is simply the URL linking to our database API server that we mentioned above, which allows controlled communication with the underlying MariaDB database.
So, in summary:
pywb needs to load a resource from a WARC file
The BnlLoader class’ overridden load() method is called
In this method, pywb makes an API call to our REST API service in order to get the S3 bucket where the WARC is stored via the database
The S3 path that is returned is then used together with the requested offset and length (provided by OutbackCDX) to make a call to the IBM S3 cluster using ibm_boto3
pywb now has all the data it needs to display the page
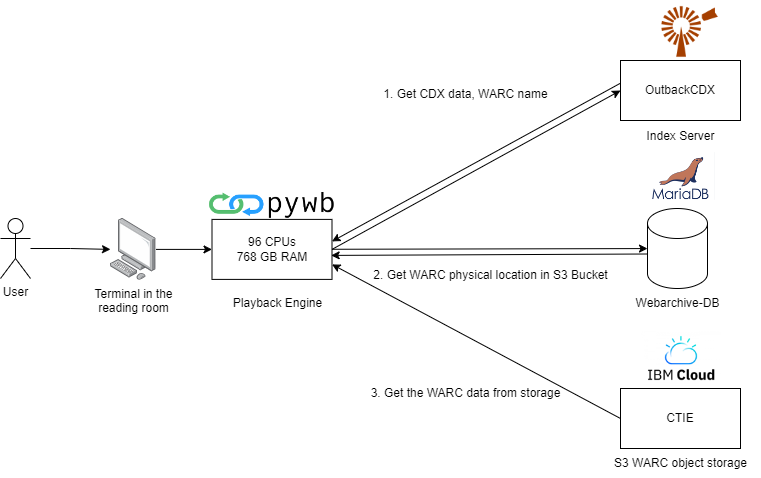
The result can be summarized in the following workflow diagram:
Figure 6: The BnL’s pywb + OutbackCDX workflow
Note that OutbackCDX and pywb are set up on the same physical server, having 96 CPUs and 768 GM RAM; however, on the diagram above, we have shown them separately for the purpose of clarity.
Our new access portal
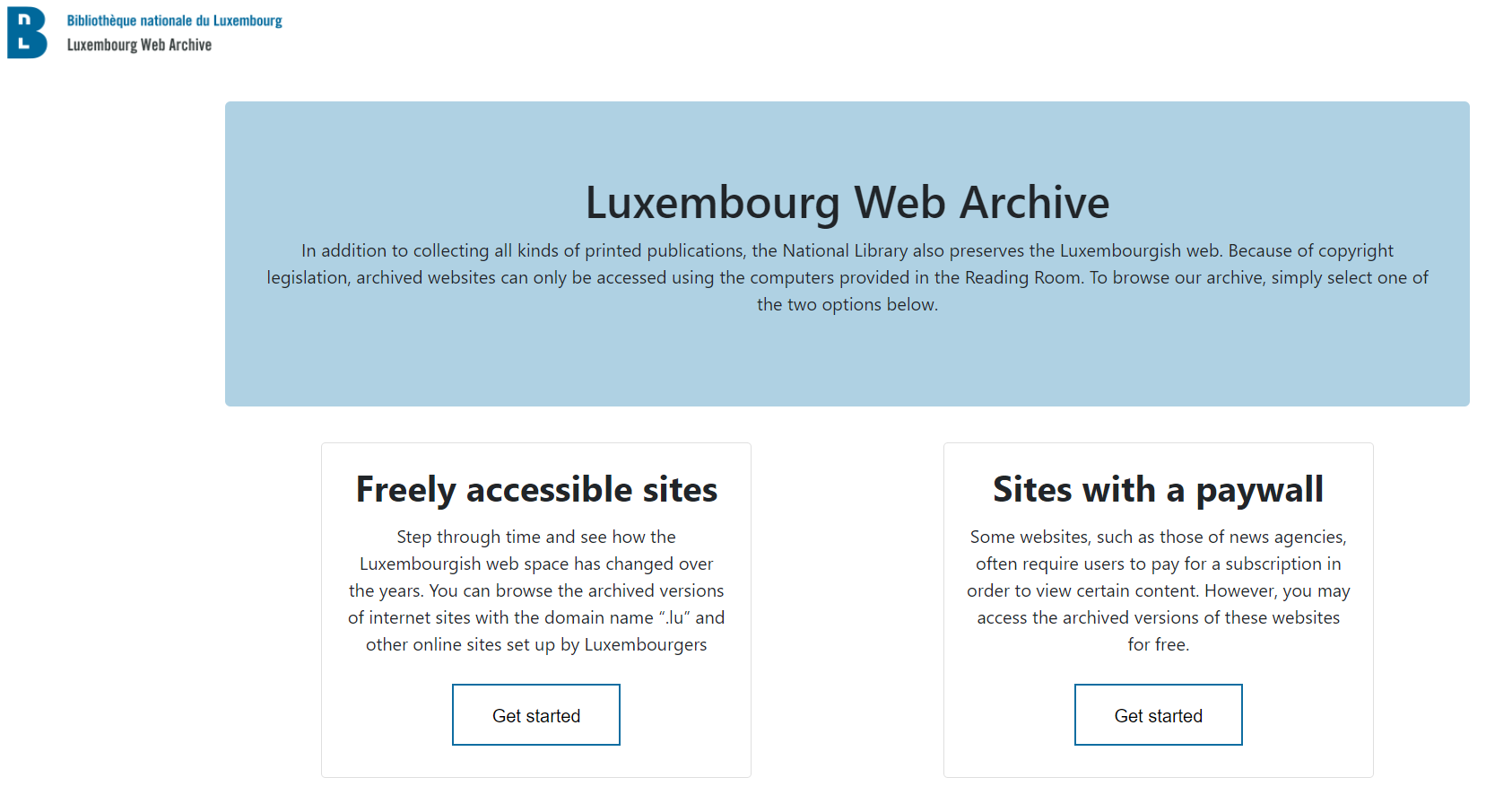
Our access portal to the web archives was also completely redesigned using pywb’s templating engine, which allows us to fully customize the appearance of almost all elements in the interface. We decided to provide our users with two main sub-portals: one for accessing websites harvested behind paywalls, and another one for everything else. We had two main reasons for this:
Several of our collections contained harvests of paywalled versions of websites. We did not want to mix these together with the un-paywalled versions,
We wanted to offer our users a clear distinction between open (“freely accessible”) content and un-paywalled content.
The screenshot below shows our main access portal:
Figure 7: The BnL’s web archive portal
Next steps
2024 will see the installation of Netarkivet’s SolrWayback at the BnL, providing advanced search features such as full-text search, faceted search, file type search, and many more. Our hybrid solution will use pywb as the playback engine while SolrWayback will be responsible for the search aspects of our archive.
The BnL will also provide an additional NSFW-filter and virus scan in SolrWayback. During indexing, the content inside the WARC files will be scanned using artificial intelligence techniques in order to label each one as “safe” or “not safe for work” material. This way, we will be able to restrict certain content, such as pornography, in our reading rooms and block other harmful elements, such as viruses.
Finally, the BnL will develop an automated QA workflow, aiming at detecting and patching missing elements after harvests. Since this work is currently being done manually by a student helper, this workflow will likely greatly increase the quality and efficiency of our in-house harvests.
Paul Koerbin is the Assistant Director of web archiving at the National Library of Australia (NLA). He is one of the pioneers of web archiving and has been involved in the IIPC since its inception in 2003, including the early meetings hosted in Canberra in 2004 and 2008 and the first Researchers Requirements Working Group meeting in London in 2004. He has represented NLA on the IIPC Steering Committee (SC) since 2018, served as Vice-Chair in 2020, chaired the WAC Program Committee (PC) in 2018 and represented the SC on the PC in the following years. Paul is also one of the custodians of the oral history of web archiving.
“Resilience is really fundamental to a sustainable web archiving programme. And then renewal. You know what’s important now, more than ever, is innovative approaches to the challenges we face whether that’s how programmes are organised within institutions or collaborations that we can form.”
From serials to social media
Olga Holownia: The pretext for this interview is your retirement and the IIPC 20th anniversary. You are one of the “oral historians” of web archiving. You have been involved in the web archiving program at the National Library of Australia since its inception in the mid-1990s and in the IIPC since its early days. If I remember correctly, the first web archivists at NLA were curators of the serials collections and this was one of the approaches used for the earliest web archive collections. In our anniversary video spotlight, you say that in the early days, web archiving was “simpler because the materials we were dealing with were simpler, the web was simpler.” As you look back, what would you consider to be the most significant moments in this journey from serials to social media?
Paul Koerbin: Yes, the web archiving team (at first known as the ‘electronic unit’ and later as ‘digital archiving section’) was established within the serials cataloguing team, where I began at the NLA. That was the ‘Australian Serials and Electronic Unit’. This was established before we actually did any harvesting. It started by selecting, cataloguing, and scoping future harvests (when we had the infrastructure to do it). So, in this context, I would suggest as one of the most significant moments – although more than a single moment – being the first actual harvesting we did, getting that very early content. But, perhaps more important, since it goes to the whole idea of resilience and sustainability, was building the specifications and then the application that became our web archiving workflow management tool (PANDAS). This, I believe, was one of, if not the, first such bespoke workflow tools for web archiving. The significance of this was to turn web archiving, quite quickly, into an operational activity, not simply a project. A quarter of a century on, the renewal of our web archiving workflow system as the fourth generation PANDAS in the past three years I think is just as significant for our web archiving operation by renewing and making the tool ever more adaptable, sustainable and fit for purpose.
On the matter of archiving being ‘simpler’ in the early days. I think I mean it was less complex, not necessarily easier. We were starting from ground zero then, building workflows, policy, and infrastructure. And the harvesting tools were obviously not as sophisticated. So, that was not simple, but a website in the early days could in many practical respects be treated like publications we were already familiar with, so perhaps what we had to deal with was conceptually simpler. However, with Web 2.0 and, of course, the later emergence of social media, the target medium has become so much more complex and both conceptually and practically more challenging to archive. Add to that the issues of preserving, managing, and making accessible huge complex collections, I think in many ways the past does look ‘simpler’. I would add that these changes are what has kept many of us involved in this enterprise for so long. It is constantly challenging and never dull!
PK: I think a crucial decision made at the very beginning of the NLA’s web archiving initiative was to treat it as a programme rather than a project. There was a 6 month period at the very beginning when it was considered a scoping project, but by the end of 1996, it was a programme incorporated into operation of the NLA’s core business to comprehensively collect Australia’s cultural heritage. I think that was visionary for the time and a crucial decision. The other decision I would mention, perhaps more a way of working rather than a stated decision, was to take a radical incremental approach to the development of infrastructure. By that I mean we did not try and solve all the problems and issues before building the applications to get operational. They were not perfect but they gave us experience and, importantly, allowed us to collect material from as early as late 1996. I think this approach built renewal – by increments – and resilience – by experience – into our web archiving programme.
OH: What have been the most rewarding experiences for you in your tenure in web archiving?
PK: Of course so much of the experience of being part of a small team over the years building the programme and building the collection of web content has been immensely rewarding. But I will highlight a couple of things: firstly, I was very involved in the framing of legislation extending legal deposit to online materials that came into force in 2016. This was the culmination of 20 years of the NLA trying to get this amendment to the legislation. The final days of preparing the bill with drafting experts in our portfolio department were exhilarating. What we emerged with was, on the whole, a broadly applicable, workable, and very successful piece of legislation. The passing of that legislation led in turn to the NLA reviewing its management of risk and the opening of access to our entire web archiving collection in 2019 as the Australian Web Archive through the Trove discovery service.
The other personally rewarding experience I would highlight would be the opportunity and privilege I have had in representing the NLA’s achievements in web archiving to the international community, through the IIPC. The NLA was a founding member of the IIPC and, despite Australia’s remoteness from the majority of the web archiving activities in the northern hemisphere, we have tried to maintain an international presence. I have found it very rewarding to have been given the responsibility by the NLA over the past 20 years to explain, promote, and represent our web archiving achievements and experiences both internationally and in Australia.
“We can’t solve all the problems alone nor recognise all the opportunities by ourselves”
OH: You mentioned the importance for NLA to be part of the international community right from the start. The IIPC has also greatly benefited from NLA’s engagement, not least with respect to creating the model for a curator workflow tool in PANDAS in the early years and more recently with open source tools, notably OutbackCDX developed by Alex Osborne. In what ways did the international collaboration contribute to the advancement of the web archiving programme in Australia?
PK: I think being part of the international web archiving community is important for the renewal of our web archiving program. At one time the NLA was a world leader and at other times we could see that there were areas where we were, perhaps, not doing so well. We can’t solve all the problems alone nor recognise all the opportunities by ourselves. I think this is the greatness of the IIPC forum. It is perhaps less about adopting tools others have developed or contributing tools to the community, though there is that too; rather it is so much about the sharing of and awareness of the diversity of approaches and the opportunities and ideas we can bring back to our own organizations and programmes. Personally, I have felt that international engagement, and seeing the achievements of others, has helped to keep me enthusiastic and driven over a long period of time to improve and promote our activities.
IIPC Steering Committee meeting, Canberra, 15 November 2004. Clockwise from right: Julien Masanes (Bibliotheque nationale de France); Caroline Wiegandt (Bibliotheque nationale de France); Pam Gatenby (NLA); Margaret Phillips (NLA); Hans Kristian Mikkelsen (Royal Danish Library); Martha Anderson (Library of Congress); Yvette Hackett (Library and Archives Canada); Svein Arne Solbakk (National Library of Norway) and Mark Middleton (British Library). Photo: Damian McDonald, National Library of Australia
Web archiving and its processes can be understood as a methodically and purposefully constructed taphonomy of the web.
Future pasts
OH: “Future pasts” was one of the topics you suggested for the 2022 Web Archiving Conference. Let me ask you your own question: how are web archives framing future perceptions of the past?
PK: Web archiving is very much an activity of taking a snapshot of the dynamic, ephemeral and relentless ‘now’ that is the world wide web, and undertaking to preserve that for a future we are yet to know. Those who will come after us will only have those fragments of the web that we have archived to understand that past. Web archiving and its processes can be understood as a methodically and purposefully constructed taphonomy of the web. The nature of the web is that it is not going to leave a trace of itself at any given time without this intervention. That is how important our work is. So much of our social discourse happens online and so much of the important ‘grey literature’ that forms the basis of social policy is published online. Without access to this, those who come after us will have no historical perspective. So, of course, this is also our tremendous responsibility, since what we choose to collect and what we are able to collect and preserve – let us remember the persistent technical, legal and resources constraints that continue to limit our activities – will frame how the future looks at the past through what we have collected and how we have preserved and provided access to it.
OH: Thank you for taking the time to answer my questions today and over the past 7 years. I have always regarded you as one of the oral historians of web archiving and you’ve always helped me fill the gaps in the early history of the IIPC. To finish off on a less sombre note, does your retirement mean that you will now have more time to dedicate to composing music for “Gumboots and Consequences”?
PK: I deny everything! (Note to readers: you had to be involved in organizing the 2018 GA-WAC in Wellington to understand the reference here. Vale the great John Clarke.) On a serious note, however, I do hope that in the near future a major IIPC event can again be hosted in Australia. The major international conference that the NLA organized in 2004 was an important milestone and the General Assembly and Conference in Wellington in 2018 (which the NLA co-sponsored and which I was involved with as co-chair of the programme committee) was a great success for the region bringing the international web archiving community to the southern hemisphere. I am hopeful that there will be another IIPC event in this region sooner rather than later.
Paul Koerbin’s closing remarks at the 2018 General Assembly hosted by the National Library of New Zealand. Wellington, 12 November, 2018. Photo: Olga Holownia, IIPC.
The call for nominations for the 2023 Steering Committee (SC) elections has closed. We received five nominations for five vacant seats, so an election process for the SC is not required this year. We would like to congratulate and thank the members who will be continuing for another term (Bibliotheca Alexandrina, Library and Archives Canada, Los Alamos National Laboratory Research Library and Swiss National Library) and also extend our congratulations to the newly elected member, University of North Texas Libraries. Please find the statements of all the nominees below. The new, three-year term starts on 1 January 2024.
We think deeply of web archiving at Bibliotheca Alexandrina (BA). We see it as an extension of the tradition of knowledge preservation that traces back to the ancient library. Joining the IIPC in 2011, BA has been active in the area of tools, contributing to ideas including data deduplication in early years and, more recently, graph visualization, and has been working in collaboration with the IIPC Research Working Group and Content Development Working Group to republish the IIPC collections for researcher access hosted on BA infrastructure. On the Steering Committee, BA has been Tools Development Portfolio lead since 2021, working with IIPC colleagues to further the development of tools for playback and capture through facilitating the pywb and Browsertrix Cloud projects, respectively. Within the academic community, BA has been promoting web archiving as a software development and data analytics topic through its popular internship program. We believe technology such as AI and VR can be transformative to how web archives are used. BA has the pleasure of having its designated representative serving as the 2023 IIPC chair, and we eagerly look forward to continuing our journey together toward maximizing the potential of archives of the web as a knowledge resource.
Library and Archives Canada (LAC) is interested in continuing its membership in the International Internet Preservation Consortium’s (IIPC) Steering Committee, which expires in 2023. LAC is a founding member of the IIPC, and has served as Chair, Vice-Chair, and Treasurer in the past. Throughout its current term, LAC has been active and has contributed to the Program Committee, and chaired sessions, at the annual conferences and at workshops (2019-present). LAC has a permanent and legislated web archiving program, demonstrating its commitment to preserving its national heritage on the web, and to the advancement of web archiving as an international digital curation-oriented discipline. While our program is not of the scale and technical complexity as others, our legislation, program management, policies and methodologies are well developed. It is in these areas LAC believes it can contribute best to the IIPC Steering Committee, leading recently to e.g., a workshop entitled “Web Archiving in a Program Management Context” to be held in October 2023. We look forward to contributing ideas and expertise for new content and workshops in the future!
LANL’s Research Library has a long-standing history of research and development efforts as well as tool development in the realm of web archiving. Most notably, members of the Prototyping Team in the library have devised the Memento Framework (RFC 7089) and implemented the Time Travel service, a system to search for archived snapshots across multiple web archives. The team has led and contributed to various research efforts, for example, a large-scale investigation into the phenomenon of link rot and content drift (reference rot) in scholarly communication and a recent analysis of the ineffectiveness of common hashes to verify fixity of replayed archived web resources. In addition, the team leads the ongoing development of Memento Tracer – a tool to support human-driven, scalable, and high-quality web archiving and contributes to the development of summarization and storytelling tools for web archive collections.
Following the institution’s representative tenure on the Steering Committee from 2020 – 2023, the we aim to continue to bring this expertise and experience to the SC. Our goal is to further promote the adoption of web archival standards, collaborative tool development to support research efforts based on web archives’ holdings, and sustainability efforts of software projects by and for the community.
The Swiss National Library (SNL) began building Web Archive Switzerland in 2008 and has been steadily expanding its collection ever since. It is currently replacing the entire long-term archiving environment and thus also the system components used for the Web Archive with a successor solution.
Since joining the IIPC Steering Committee, the SNL has held various roles, including the Chair 2019. The SNL representative also took over the leadership of the Strategic Decisions Working Group in 2020 to ensure continuity in the work on the Consortium Agreement. The SNL would very much like to continue supporting the implementation of the Strategic Plan by participating actively and is therefore running for another term of office.
In the opinion of the SNL IIPC’s greatest strength is its ability to bring together different communities of as well as researchers as well as practitioners and to provide easy access to the topic of web archiving. We also believe that the IIPC should continue to serve as a technologically well aligned competence center for web archiving. In concrete terms, this means a forward-oriented strategy with anticipation of future developments (e.g. related tools, preservation practices, metadata, big data, artificial intelligence)
The University of North Texas (UNT) Libraries, serving 44,000+ students and faculty, is committed to providing a wide range of resources and services to our users. We feel that the preservation of and access to Web archives is an important component of these services. We crawl and serve content on locally hosted infrastructure and develop tools for working with WARCs. Members of the libraries offer a Web Archiving course in the College of Information and conduct grant-funded research with web archives.
An IIPC member since 2007, the UNT Libraries has served previous terms on the Steering Committee. Recently, members of the UNT Libraries have worked as co-chairs of the Tools Development Portfolio, on the Partnership and Outreach Portfolio, on the Discretionary Funding Program selection committee, on the WAC program committee, and on the Browser-Based Crawler project.
With an interest in supporting tools development, facilitating research with Web archives, preservation of archived material, and growing IIPC membership, the UNT Libraries wishes to serve on the Steering Committee. If elected, the UNT Libraries will represent the unique concerns of research libraries as well as continue to support the needs of other IIPC member institutions.
Link to album: https://flic.kr/s/aHBqjAGaxc Credits: Jacqueline van der Kort (Beeldstudio KB), Ode-Louise Eshuis (www.byode.nl) & Olga Holownia.
The IIPC annual General Assembly (GA) and Web Archiving Conference (WAC) are the most important events on the IIPC calendar. They have long provided a forum for our members and the broader web archiving community to present their work, exchange ideas, and network. For us, each GA and WAC represents a new collaboration with hosting member institutions as we build connections with different hosts and web archiving teams every year. We had the pleasure of co-organizing GA and WAC with not one but two member institutions this year: the Netherlands Institute for Sound and Vision and KB, the National Library of the Netherlands.
The 2023 WAC marked the first in-person IIPC event in four years, since the 2019 conference in Zagreb, and it took some time to adjust and prepare for a face-to-face gathering. The organization of in-person events always presents its own set of challenges, and effective communication with the local team is crucial. We were very fortunate to work over the course of nine months with our excellent colleagues from KB and Sound & Vision on the organizing committee, all of whom went above and beyond to help make the conference a success. We were uncertain about the transition back to an in-person conference after such a lengthy break until the start of the GA – from the first moments of the registration and coffee hour, the atrium was buzzing with excitement, an atmosphere that could not be replicated on Zoom. We loved getting to meet delegates in-person for the first time, and it was also great to reconnect with delegates we met at previous conferences.
#webarchivering
The 2023 IIPC annual event returned to the Netherlands after 12 years: previously, in May 2011, the IIPC General Assembly was heldat KB in the Hague in May 2011. This year, KB hosted the 2023 Steering Committee meeting. The 2023 GA and WAC took place in Hilversum, in the Netherlands Institute for Sound & Vision’s refreshingly colorful building that houses one of the largest audiovisual collections in Europe as well as a newly opened Media Museum and web archiving collection of audiovisual content. The conference began with a high-energy start with opening remarks from Sound & Vision’s Eppo van Nispen, setting the tone for a busy and enthusiastic few days of web archiving discussions.
Our opening keynote by Eliot Higgins of Bellingcat discussed the importance of open source investigation, leading to a thoughtful Q&A chaired by Sound & Vision’s Johan Oomen.
The conference closing keynote by Marleen Stikker of Waag Futurelab (chaired by Martijn Kleppe from KB) highlighted the story ofthe Digital City, provoking a conversation on public values in the digital domain.
Jeffrey van der Hoeven of KB (and IIPC’s 2023 Vice-Chair) ended the program with a thoughtful closing speech that showcased all of the work of the 2023 GA&WAC, and that highlighted the words of former KB colleague Kees Teszelsky: “Keep archiving & keep collecting and describing your own heritage. A collection without context is only half of use for researchers.”
Photo of Tamara van Zwol (Dutch Digital Heritage Network) and panelists from IIPC WAC 2023 Public Event: Building Digital Heritage Together: Dutch and Transnational Perspectives, 10 May. Photo credit: Jacqueline van der Kort; Beeldstudio KB| nationale bibliotheek
This year, the authors and delegates across all events represent over 170 organisations from over 40 countries.We were fortunate to bring together around 90 presenters for the in-person and online WAC. We immensely appreciate our presenters for sharing their time and expertise with us, as well as for their willingness to share slides and recordings of talks, which has enabled us to add to our growingcollection of web archiving resources available online. We also had several excellent workshops, lightning talks, and drop-in talks at the conference in Hilversum.
This year’s program also saw the launch of a Mentoring Program organized by the IIPC Membership Engagement Portfolio, pairing experienced mentors with delegates that were new to the conference or to the web archiving profession. This year’s Mentoring Program saw 16 mentor/mentee matches and we are hoping to offer this networking opportunity again at our future conferences.
Online Day
We have always provided online meetings and workshops to connect with our global membership. The range of these events was significantly increased in 2017 with the addition of our research and technical webinars. Due to the pandemic, we had to boost our online offerings even more, including running the last few WACs (co-hosted by the National Library of Luxembourg in 2021 and the Library of Congress in 2022) entirely online. The 2023 Online Day allowed us to cover different time zones and made sure that we could offer at least one day of programming to those who couldn’t travel to Hilversum. This year we used the format developed for previous online editions of WAC, which comprised pre-recorded talks made available to conference delegates ahead of WAC and live Q&A sessions. Both pre-recorded talks and recorded Q&As for the WAC 2023 Online Day are also now available on YouTube.
The General Assembly
Link to album: https://flic.kr/s/aHBqjAGaxc Credits: Jacqueline van der Kort (Beeldstudio KB), Ode-Louise Eshuis (www.byode.nl) & Olga Holownia.
The General Assembly has been a member benefit from the early years of the IIPC. First hosted by the National Library of France in 2007, the IIPC annual event gradually expanded to include Open Days, now known as WAC. The GA has been highly valued for its practitioner-oriented content, fostering informal networking opportunities and facilitating important strategic discussions within the consortium.
This first return to an in-person meeting since 2019 was a big success with 39 member institutions from 27 countries attending.
The GA is an excellent opportunity for IIPC networking and catching up in-person, as well as a chance for Working Groups to meet and plan for the next season of events. It is also an opportunity for members to get updates on IIPC activities and planning. This year’s General Assembly program began with an address from IIPC’s 2023 Chair, Youssef Eldakar from Bibliotheca Alexandrina. Reports from the 2023 Executive Board, Working Groups, and Portfolios followed, and then there were member updates after a break. The afternoon’s program included meetings for each of our working groups: Content Development, Research, Training, and the Tools Portfolio. It was wonderful to see so many of our members in-person, and to hear their updates. We also launched our 2023 Member Survey and Member Activity Survey at the GA, a Membership Engagement Portfolio initiative that will shape future programming and IIPC strategic planning.
Thank you!
Organization of our annual events would not have been possible without the incredible support of our members. Our Program Committee was, as always, outstanding, and we would like to thank all the volunteers who chaired sessions during the online and in-person events. We would particularly like to thank Lauren Ko (University of North Texas), Paul Koerbin (National Library of Australia), and Meghan Lyon (Library of Congress) for providing additional assistance with the 2023 conference theme, program, and reviews. For the third year in a row, we’ve also been lucky enough to work with Robin Saklatvala to deliver the online day.
We’ve already mentioned the amazing work of the 2023 Organizing Committee, all of whom worked tirelessly to make this year’s conference a success. We’d also like to thank the staff at Sound & Vision for all of their help. All of their work was crucial to the conference’s success, from the excellent catering staff and chef providing our attendees with delicious food and coffee, to the hard-working audiovisual technicians for making sure that presentations were able to run smoothly, to Marloes and Rachel’s incredible help managing the registration desk. Thank you also to our student volunteers for their support during the conference.
We would also like to thank the UNT Digital Library for working with us for the past five years to provide a home for slides and other IIPC materials, making them accessible, well-preserved, and easily citable. The 2023 presentations are available in the IIPC Conference collection.
Last but not least, we’d like to thank all GA and WAC 2023 delegates for attending both online and in person. Your questions to presenters, engaging discussions during breaks, and presence at the conference and the Online Day all helped to make the conference what it was. Thank you also to our GA and WAC delegates for providing us with such great and thorough feedback. We’ve used it to help prepare the 2024 WAC Call for Proposals and will be considering it further in the organization of future events.
There have been some wonderful post-conference blog posts, summarizing some of the highlights for different conference attendees. It has been great to see what had the biggest impact for delegates at the 2023 conference! We have included a list of these posts below, and will keep updating it as new materials become available. Please feel free to contact us if you have a post that isn’t yet included.
We’re now taking the opportunity to invite everyone to both explore the 2023 collection of recordings and slides and to submit a proposal for the 2024 conference hosted by the National Library of France. We hope to see you all in Paris next year!
By Peter Chan, Web Archivist at Stanford Libraries
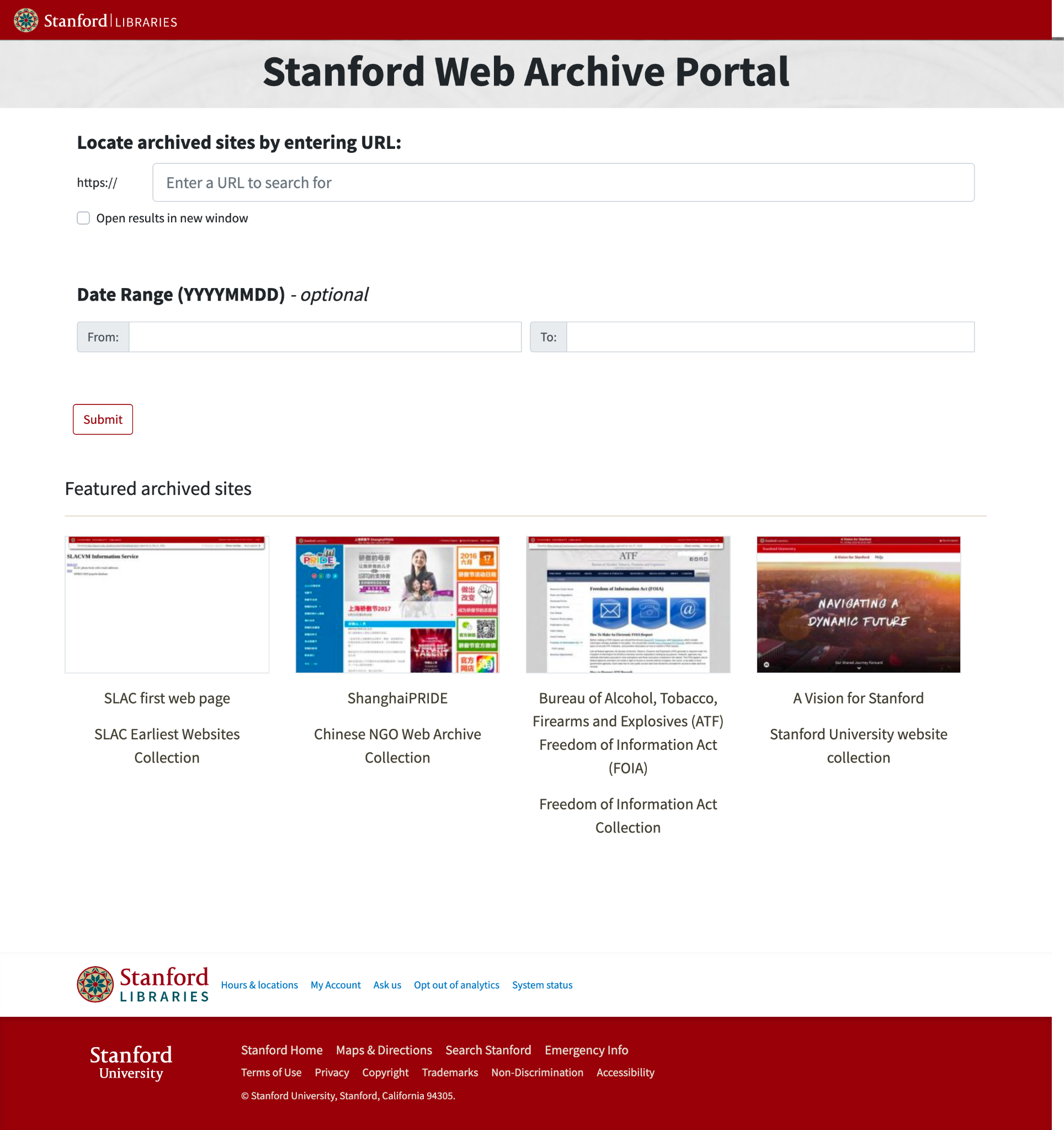
Navigating the vast ocean of websites archived by organizations such as Stanford University Libraries, Internet Archive, National Libraries, and other University Libraries can be a daunting task. The purpose of this blog post is to provide a roadmap of possible strategies that Stanford Libraries can adopt to aid researchers in effectively using our web archive (captured by Archive-It). These websites are housed at Stanford and displayed through pywb. I acknowledge that different institutions may have varying set-ups and tools in place to help researchers. However, my hope is that this post will prove beneficial to the broader web archiving community.
Locating Specific Text on a Page
The simplest way to locate specific text on a webpage is by utilizing the ‘Find’ function on your keyboard. This can be activated by pressing Ctrl+F if you’re using a Windows PC, Chromebook, or Linux system, or Command+F if you’re on a Mac. This function is a standard feature across all browsers. It’s such a basic tool that people often forget it’s there, but a quick reminder can help users make the most of this handy feature. Should your exploration extend beyond a single webpage, you may find the need to employ the advanced tools discussed in the subsequent sections.
Employing Full Text Search for Websites
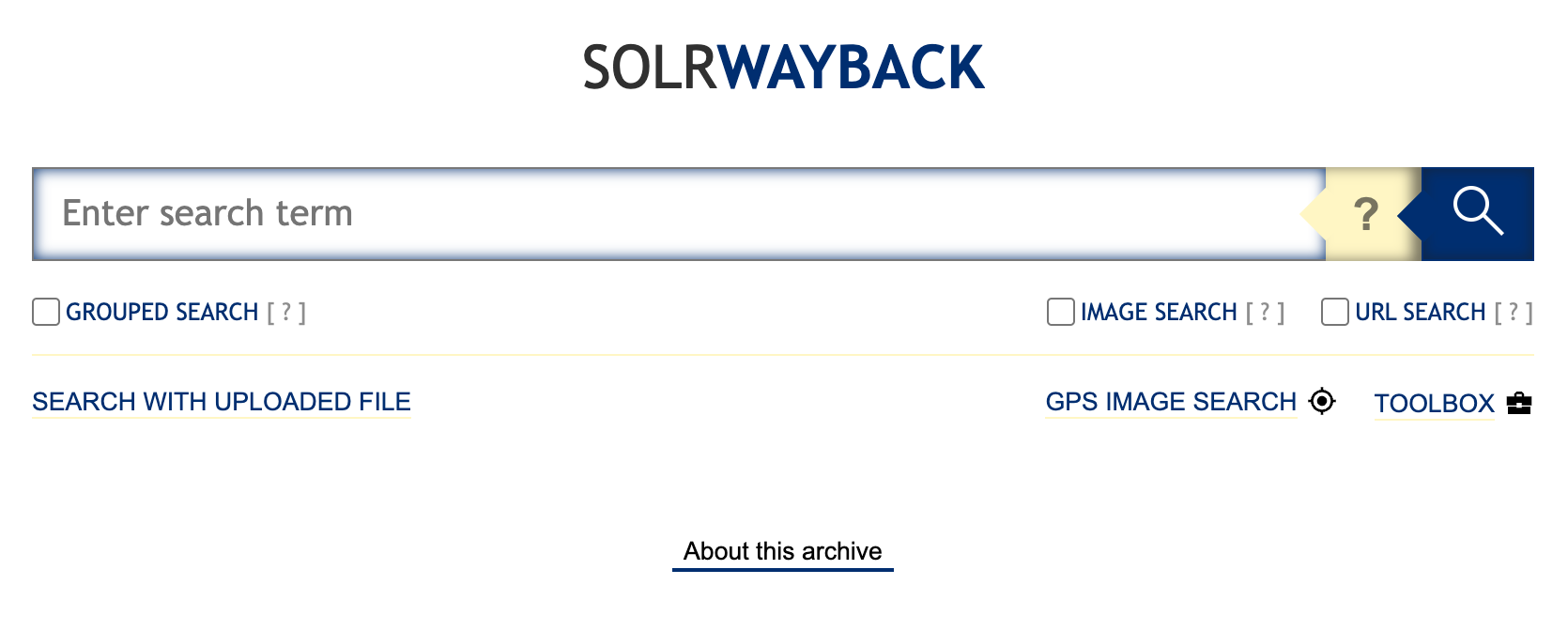
If you have access to WARC files that you wish to analyze, deploying SolrWayback could be a worthwhile option to explore. This software (developed by the Royal Danish Library) is specifically designed to facilitate navigation through historical ARC/WARC files. It allows for free-text searching across multiple resources, such as HTML pages, PDFs, URLs, media metadata, and more. Additionally, it includes an interactive link graph for domains, giving insight into both incoming and outgoing connections. More details can be found here: https://netpreserveblog.wordpress.com/2021/02/25/solrwayback-4-0-release-whats-it-all-about/.
SolrWayback is used by the British Library, the Royal Danish Library, the Bibliothèque nationale de France and others.
If you don’t have the technical capabilities to implement SolrWayback and your archived sites have been indexed by Google, you could recommend that your users utilize Google Search as an alternative. To limit the search to a particular website, type “site:” into the Google search bar followed by the website’s name. Then, after a space, enter the search term. For instance, input “site:https://swap.stanford.edu/was/ foia” into the search bar, hit “Return or Enter,” and the results will display any article from https://swap.stanford.edu/was/ containing the word “foia”.
Navigating Through Entity Extraction, Domain Analysis, Network Diagram & More
For digital humanities scholars seeking a more in-depth exploration, the Internet Archive provides the Archives Research Compute Hub (ARCH). ARCH is designed to assist users in conducting and supporting computational research on a large scale with digital collections. This includes areas like text and data mining, data science, digital scholarship, machine learning, and others. Users have the opportunity to create bespoke research collections pertaining to an extensive range of subjects, produce and access datasets ready for research from these collections, and carry out analyses on these datasets. Consistent with the best practices for reproducibility, ARCH enables open publication and preservation of user-generated datasets.
Engaging with Generative AI-Powered Question and Answer Systems
Recent advancements in generative artificial intelligence have paved the way for user interaction with computer systems using various natural languages such as English, Chinese, and others. AI tools such as ChatGPT, Google Bard, and HuggingChat are increasingly being employed across a multitude of fields like email composition, coding, content generation, tutoring in various subjects, language translation, video game character simulation, among others. These tools harness the power of large language models like GPT-4, PaLM 2, and Falcon 40B, which are trained until a certain cutoff date, to generate responses. They are adept at interpreting user queries and delivering valuable insights.
However, they do have limitations, particularly when addressing questions that require information beyond their training cut-off date. In these situations, these tools may generate responses that are not backed by the available data, essentially inventing answers. To avoid this, these AI tools can be set up to constrain their responses to designated data sources via plugins like Web Request.
As an example, when I asked ChatGPT with the Web Request plugin, “What is this site https://wayback.archive-it.org/8751/20230513070138/https://stanfordhatesfun.com/ about,” the response was, “The website ‘stanfordhatesfun.com’ appears to be a channel for expressing dissatisfaction with certain Stanford University policies and actions. It is part of the Stanford Activism collection and has been archived by the Stanford University Archives…”
The Internet Archive has also introduced an experimental tool “IA Copilot” to interact with the web archive content in the Wayback Machine using ChatGPT.
Note: This blog was created with the assistance of ChatGPT. I would like to express my gratitude to Josh Schneider, Olga Holownia, and Edward Summers for their valuable input and suggestions regarding the blog. If you are interested in studying any of Stanford’s web archive collections, please feel free to contact me at pchan3 AT stanford.edu.
The Steering Committee (SC) is composed of no more than fifteen Member Institutions who provide oversight of the Consortium and define and oversee action on its strategy. This year, five seats are up for election.
What is at stake?
Serving on the Steering Committee is an opportunity for motivated members to help guide the IIPC’s mission of improving the tools, standards and best practices of web archiving while promoting international collaboration and the broad access and use of web archives for research and cultural heritage. Steering Committee members are expected to take an active role in leadership, contribute to SC and Portfolio activities, and help guide and administer the organisation. The elected SC members also lead IIPC Portfolios and thus have the opportunity to shape the Consortium’s strategic direction related to three main areas: tools development, membership engagement and partnerships. Every year, three SC members are designated as IIPC Officers (Chair, Vice-Chair and Treasurer) to serve on the IIPC Executive Board and are responsible for implementing the Strategic Plan.
Who can run for election?
Participation in the SC is open to any IIPC member in good standing. We strongly encourage any organisation interested in serving on the SC to nominate themselves for election. The SC members meet in person (if circumstances allow) at least once a year, usually before the General Assembly. Face-to-face meetings are supplemented by two teleconferences plus additional ones as required.
Please note that the nomination should be on behalf of an organisation, not an individual. Once elected, the member organisation designates a representative to serve on the Steering Committee. The list of current SC member organisations is available on the IIPC website.
How to run for election?
All nominee institutions, both new and existing members whose term is expiring but are interested in continuing to serve, are asked to write a short statement (max 200 words) outlining their vision for how they would contribute to IIPC via serving on the Steering Committee. Statements can point to past contributions to the IIPC or the SC, relevant experience or expertise, new ideas for advancing the organisation, or any other relevant information.
All statements will be posted online and emailed to members prior to the election with ample time for review by all membership. The results will be announced in October this year and the three-year term on the Steering Committee will start on 1 January2024.
Below you will find the election calendar. We are very much looking forward to receiving your nominations. If you have any questions, please contact the IIPC Senior Program Officer (SPO).
Election Calendar
16 June – 12 September 2023: Nomination period. IIPC Designated Representatives are invited to nominate their organisation by sending an email including a statement of up to 200 words to the IIPC SPO.
13 September 2023: Nominee statements are published on the Netpreserve blog and Members mailing list. Nominees are encouraged to campaign through their own networks.
13 September – 10 October 2023: Members are invited to vote online. Each organisation votes only once for all nominated seats. The vote is cast by the Designated Representative.
12 October 2023: The results of the vote are announced on the Netpreserve blog and Members mailing list.
1 January 2024: The newly elected SC members start their three-year term.
By Friedel Geeraert, Expert in web archiving at KBR | Royal Library of Belgium
The IIPC Web Archiving Conference 2023 took place in Hilversum in The Netherlands at the beautiful building of Sound and Vision. The warm atmosphere of the web archiving community gathered there more than compensated for the cold rain outside. Over the two day conference, presentations were given about themes such as new initiatives and collections, COVID-19, collaborations, digital scholarship and research, tool development, quality assurance, outreach, inclusive representation, data management, preservation and infrastructure. The different workshops organised during both days provided the opportunity to gain more hands-on experience. The programme was so interesting that it was difficult to choose which track to follow or which workshop to choose.
Netherlands Institute for Sound and Vision in Hilversum Photo: Olga Holownia | IIPC
Open Source Investigation and Public Values in the Digital Domain
The two keynote speakers, Eliot Higgins of Belligcat and Marleen Stikker of Waag Futurelab shared their expertise and vision. Higgins provided insight into Bellingcat, the independent group of investigative journalists and their ethical digital investigation into conflicts such as the war in Ukraine to debunk misinformation. Bellingcat also initiates programmes to teach students to think critically about online information and sources, thereby helping them to make better informed decisions and formulate well-founded opinions, which is hopeful in light of the polarisation of society.
Eliot Higgins | Bellingcat & Johan Oomen | Sound & Vision Photo: Olga Holownia | IIPC
Stikker explained her alternative history of the internet focusing on the social roots instead of its military origins and the role we can all play into managing the internet as a commons and govern it accordingly. She suggests assessing the foundation by asking critical questions about the underlying assumptions and the organisation of government, guaranteeing human rights and ensuring a regenerative socio-economic model (as opposed to the current extractive model). Above all, she argues for undertaking action by for example moving towards platforms that are not governed by big commercial corporations such as Signal and Mastodon.
Marleen Stikker | Waag Futurelab Photo: Olga Holownia | IIPC
Thoughts, tips and takeaways
As always, participants came away with their heads filled with ideas and useful information. Armed with numerous pages filled with notes and lists of people I need to contact in the coming months to obtain more information, I returned to KBR in Belgium. I will be using the coming year to further look into ARCH, the Archive Research Compute Hub, developed by the Archives Unleashed Project, the Browsertrix Cloud, developed by the Webrecorder team and SolrWayback, developed by the Danish Royal Library. Providing more descriptive information about web archive collections was another interesting idea that was evoked by the web archiving team of the BnF and by Emily Maemura and Helena Byrne as well in their ‘datasheets for datasets’ concept.
“Describing Collections with Datasheets for Datasets” workshop Photo: Jacqueline van der Kort | Beeldstudio KB
Jefferson Bailey | Internet Archive, ARCH workshop Photo: Jacqueline van der Kort | Beeldstudio KB
Other aspects that sparked my interest are preservation practices in the context of web archiving, for example WARC validation presented by the team of the National Archives of the Netherlands, the need for consistent use of data repositories such as Zenodo, Software Heritage and the Internet Archive and the use of the URN PWID to reference web archive sources. Other ideas that arose during the conference were linked to quality assurance and analysis: the use of tools such as Screaming Frog by the team at the UK Government Web Archive, the WAVA tool (Web Visualisation and Analysis), developed by the team behind the Web Curator Tool, and the use of rubrics as demonstrated by the speakers of the Library of Congress. The team behind the End of Term web archive also talked about tools used by CommonCrawl that are promising to create derivative datasets and enriched metadata.
Community coming together
These are only a few examples of the wealth of interesting ideas evoked at this conference but on top of that it was wonderful to catch up with other members of the web archiving community during the breaks. Over cups of coffee, delicious ciabatta and sweet pastries, topics of conversation ranged widely from planned changes to national legislations, evolutions in Twitter collection policies and public tenders on one end of the seriousness spectrum, with the sock affinity of an awfully cute puppy and discussions about the best gifts to give to 6 month old babies on the other end. Many thanks for the organisers of this year’s conference for such a great edition of the IIPC WAC. Needless to say, I’m already looking forward to next year’s edition on April 25-26, 2024 hosted by the BnF.









 The call for nominations for the 2023 Steering Committee (SC) elections has closed. We received five nominations for five vacant seats, so an election process for the SC is not required this year. We would like to congratulate and thank the members who will be continuing for another term (Bibliotheca Alexandrina, Library and Archives Canada, Los Alamos National Laboratory Research Library and Swiss National Library) and also extend our congratulations to the newly elected member, University of North Texas Libraries. Please find the statements of all the nominees below. The new, three-year term starts on 1 January 2024.
The call for nominations for the 2023 Steering Committee (SC) elections has closed. We received five nominations for five vacant seats, so an election process for the SC is not required this year. We would like to congratulate and thank the members who will be continuing for another term (Bibliotheca Alexandrina, Library and Archives Canada, Los Alamos National Laboratory Research Library and Swiss National Library) and also extend our congratulations to the newly elected member, University of North Texas Libraries. Please find the statements of all the nominees below. The new, three-year term starts on 1 January 2024.