By the AWAC2 (Analysing Web Archives of the COVID-19 Crisis) team: Susan Aasman (University of Groningen, The Netherlands), Niels Brügger (Aarhus University, Denmark), Frédéric Clavert (University of Luxembourg, Luxembourg), Karin de Wild (Leiden University, The Netherlands), Sophie Gebeil (Aix-Marseille University, France), Valérie Schafer (University of Luxembourg, Luxembourg)
As mentioned by Nicola Bingham in her blog post “IIPC Content Development Group’s activities 2019-2020” in July 2020, a huge effort has been made by the Content Development Group and IIPC members to create a unique collection of web material related to the pandemic, with contributions from over 30 members as well as public nominations from over 100 individuals/institutions.
This collection immediately attracted the interest of researchers because of the quantity of collected data, its transnational nature and the many possibilities it offers to explore web archives of this unprecedented period at an international level.
A strong interest in COVID-19 collections in WARCnet
The WARCnet project was launched at the beginning of 2020, just as the world was witnessing the first developments in the COVID-19 crisis.
WARCnet is a network of researchers and web archiving institutions (see WARCnet team) which aims to promote transnational research that will help us to understand the history of (trans)national web domains and transnational events on the web, drawing on the increasing volume of digital cultural heritage held in national web archives (Brügger, 2020). The network’s activities started in 2020 and will run until to 2023, and they are funded by the Independent Research Fund Denmark | Humanities (grant no 9055-00005B). The network is organised into six working groups, with working group 2 (WG2) focusing on the study of transnational events through web archives.
WG2 decided to select the COVID-19 crisis as one of its first case studies and test beds, and it conducted a first distant reading of several collections related to the crisis, combining metadata from the special collections of national institutions like the British Library, the BnF (National Library of France) and INA (the French National Audiovisual Institute) in France, the BnL (National Library of Luxembourg), etc., with the IIPC collection. The WG2 received metadata in the form of seed lists of these collections thanks to web archiving institutions and a special agreement with them.
At the same time a series of oral interviews were carried out with web archivists and web curators to shed more light on the selection and curation processes and the scope of these special collections, including an interview by Friedel Geeraert with Nicola Bingham on the IIPC collection (Geeraert and Bingham, 2020). Transcriptions of this series of oral interviews are available online for free download. You will find interviews with web archivists and curators working at INA, the BnF, the BnL, the IIPC, Netarkivet (Denmark), the National Széchényi Library in Hungary, the UK Web Archive, the Swiss National Library, the National Library of the Netherlands (KB) and the Icelandic Web Archive. Other interviews are scheduled.
An internal WG2 datathon on the metadata received from web archiving institutions held at the very beginning of 2021 enabled us for example to compare national collections with one another and with the selection they made for the IIPC coronavirus collection (table 1) and to measure the websites that emerged during the pandemic (table 2). Another goal of WG2 was to compare the metadata provided by institutions (table 3) and the way they could be intertwined.

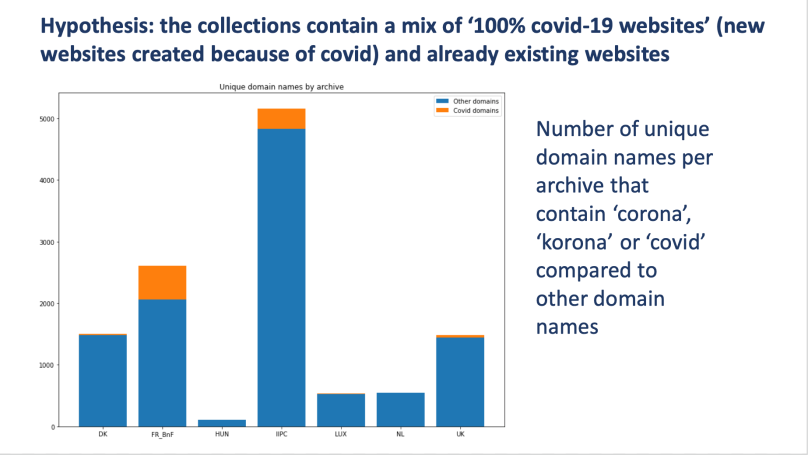

The data was provided by the following web archives: RDL (Royal Danish Library); BnF; NSL (National Széchényi Library, Hungary); IIPC; BnL; KB (Koninklijke Bibliotheek, the Netherlands); UKWA (UK Web Archive).
A new opportunity and a multi-partner collaboration
This first exploration led to the desire to go deeper into COVID-19 collections, and a unique chance was offered to us when the Archives Unleashed team launched its annual call for cohorts.

Some of the WG2 members therefore decided to submit a proposal entitled AWAC2, which stands for “Analysing Web Archives of the COVID-19 Crisis through the IIPC Novel Coronavirus Dataset”. With this application, we hoped to deepen our understanding of the IIPC COVID-19 collection at several levels:
First, it was a way to continue our initial distant exploration of (meta)data, in order to answer qualitative questions such as:
(1) Participation in the collection by web archiving institutions and web archive representatives
— how many URLs inside/outside ccTLDs?
— can we indirectly document some countries with no national web archives through this collection?
— comparison of national collections and their selection for IIPC (based on Danish and Luxembourgish collections)
(2) Categories of stakeholders, websites, representativeness and inclusiveness
(3) New event-specific websites
(4) MIME types and visual studies
(5) Hyperlink networks
What characterises the hyperlink network of websites included in the IIPC collection? Can any national website clusters be identified? (This analysis could be performed in Gephi).
Second, it was an opportunity to obtain complementary data and to combine research methods, especially distant and close reading, thanks to the possibility of accessing full text.
Third, it was also a unique chance to further explore the possibilities offered by the Archives Unleashed tools that the team has been developing for many years, which we were introduced to with the pre-workshop organised by Ian Milligan and Nick Ruest at the 2019 RESAW conference in Amsterdam and have been following ever since through reports about their activities and academic papers (Ruest et al., 2020). It was also an opportunity to benefit from regular discussions with the team, enrich our computational skills and create a research dynamic with an efficient and impressive team in Canada.
Finally, it was a way to explore new research questions that we had in mind from the beginning, and which are more related to topical approaches (e.g. Women, gender and COVID-19). We will come back to this in the last section.
First exciting steps
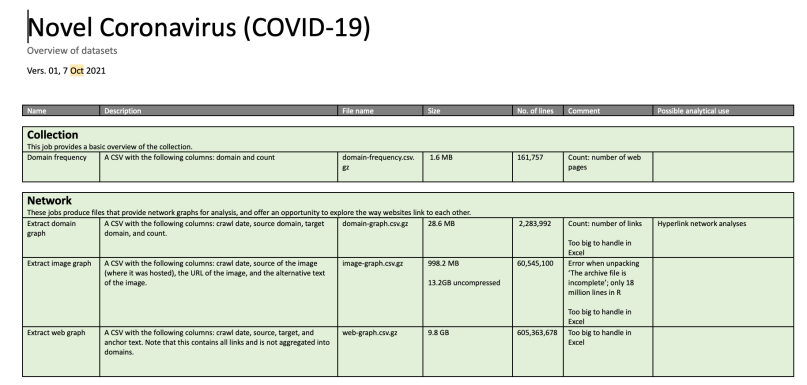
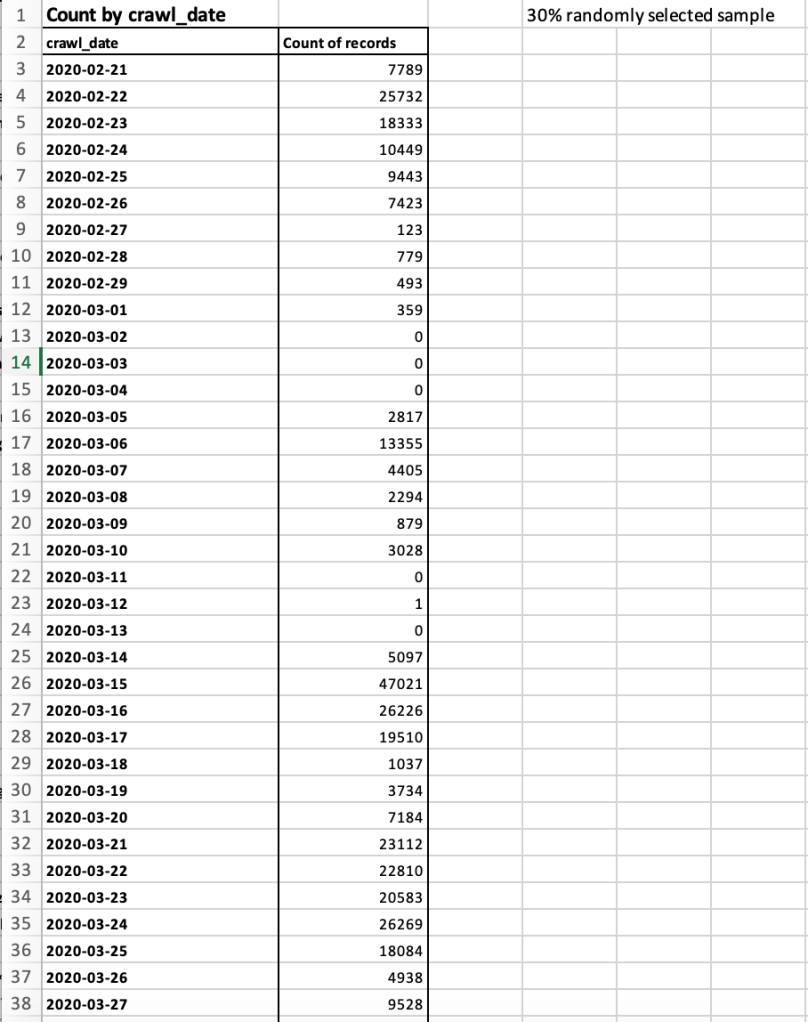
We are very thankful to the IIPC, Archive-It and the Archives Unleashed team for selecting our project and for the agreement that was signed to access this large dataset. Since the end of August, following the launch of the Cohort Programme in July 2021 that enabled us to meet all the participants and cohorts in the yearly programme, the AWAC2 team has been able to explore the new Archives Unleashed interface within Archive-It and the many datasets and visualisations that have been made available to us (figures 1 and 2).


The technical skills within the AWAC2 team are heterogeneous and while some members immediately began analysing data, others initially struggled to download some datasets, as the collection contains a huge amount of data and requires computer skills. However, the team is now on track and greatly benefits from the two regular monthly meetings with the Archives Unleashed team, whose availability to answer questions, explore technical issues with us and share (and explain) notebooks is amazing.
The AWAC2 team immediately started mapping data, framing the scope (table 4), discussing methods and creating samples to study several aspects related to multilingualism and stakeholders represented in web archives (tables 5 to 8).



Full text access also gives us an opportunity to combine methodologies and use tools like Iramuteq that allow text mining. This is the next step we are hoping to achieve…
Taking things further… with you!
To deepen collaboration with IIPC members and continue the fruitful dialogue that we began when we started by exploring the IIPC collection, we will of course continue to share our results and our insights into the crisis gleaned from web archives and this COVID-19 collection, which may in itself become an object of study as a mirror of web archiving practices, curation and methodologies. We also want to respond to the interest of the IIPC community by sharing our research questions with you, and we would like to invite you to vote for the research questions that we should investigate first.
The multidisciplinary nature and wide-ranging fields of expertise of the team have led to a long list of research interests, and the team is planning to meet for three days in March 2022 to conduct a test bed on one or two case studies. Our case studies will be the ones that you select:
- Research on Women, Gender and COVID-19 within this collection (e.g. domestic violence, care and homeschooling, etc.). We will probably use Iramuteq or Mallet on derivative files to perform text mining.
- Identify private journals of lockdowns, individual traces of daily life and different online expressions that offer insights into the ways people are dealing with COVID-19 in their everyday lives.
- Trace public support/opposition to lockdown. Can we conduct a sentiment analysis over time?
- How was the home schooling debate conducted on the web? How did the various stakeholders communicate about it?
- How to identify fake news, conspiracy theories and other COVID 19-related controversies within these big data?
- Is it possible to perform a visual analysis of what medical-scientific communication on COVID-19 looks like (and what type of visual communication is used, e.g. graphs, visuals, colours)?
- The pandemic seriously affected museums around the world and in some countries the web became a prominent channel for their communication. How did museum websites evolve during the COVID-19 pandemic?
Please select your two top case studies at https://www.surveymonkey.com/r/BRRX57T by 20 December 2021. Your choice will be ours! We are looking forward to discovering your selection.
References
Bingham Nicola, “IIPC content development Group’s activities 2019-2020”, Netpreserve Blog, 2020.
https://netpreserveblog.wordpress.com/2020/07/01/iipc-content-development-groups-activities-2019-2020/
Brügger Niels, “Welcome to WARCnet”, Aarhus, WARCnet Paper, 2020.
https://cc.au.dk/fileadmin/user_upload/WARCnet/1.Bru__gger_Welcome_to_WARCnet.pdf
Geeraert Friedel and Bingham Nicola, “Exploring special web archives collections related to COVID-19: The case of the IIPC Collaborative collection. An interview with Nicola Bingham (British Library) conducted by Friedel Geeraert (KBR)”, Aarhus, WARCnet Paper, 2020.
https://cc.au.dk/fileadmin/user_upload/WARCnet/Geeraert_et_al_COVID-19_IIPC__1_.pdf
Ruest Nick, Fritz Samantha, Deschamps Ryan, Lin Jimmy, Milligan Ian, “From archive to analysis: accessing web archives at scale through a cloud-based interface”, International Journal of Digital Humanities, 2021.
Software:
- IRaMuTeQ https://iramuteq.org/
- Pandas https://pandas.pydata.org/
- Altair https://altair-viz.github.io/

[…] Read how an international research team uses these tools to explore COVID-19 web archive data here on the IIPC blog and learn where the development project goes next with the program update […]
LikeLike
[…] Just precisely how future scholars, students, and neighbors will access the local memory of COVID-19 is a fascinating area of ongoing research and experimentation. In addition to the Wayback replay and full-text search tools to which veteran web archivists are accustomed, Archive-It partners are now also exploring brand new ways to represent and visualize their collected data. Case studies in integrating Archive-It’s platform with data processing tools are new, but started immediately with collections that represent different experiences of COVID-19, like this international effort. […]
LikeLike
[…] year ago, a post on this very blog (“Analysing Web Archives of the COVID-19 Crisis through the IIPC collaborative collection: early findi…” 2 November 2021) invited the IIPC community to vote for a more specific topic that the AWAC 2 […]
LikeLike
[…] Analysing Web Archives of the COVID-19 Crisis through the IIPC collaborative collection: early findi… […]
LikeLike